ATT&CK 2022 Roadmap

Where We’ve Been and Where We’re Going
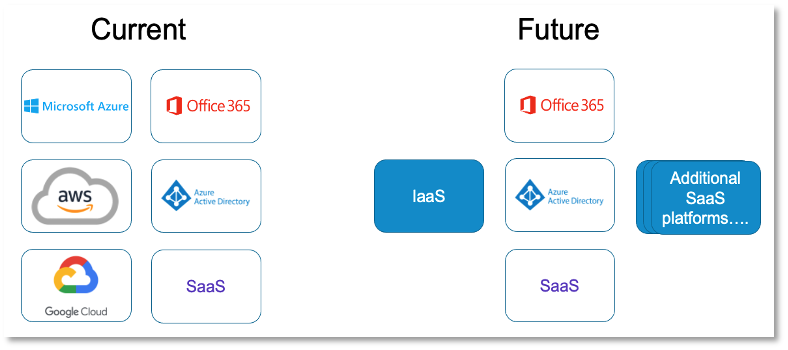
In 2021, as we navigated a pandemic and moved into a new normal, we continued evolving ATT&CK without any significant structural overhauls (as promised). We were able to make strides in many areas — including the ATT&CK data sources methodology, to more effectively represent adversary behavior from a data perspective. We refined and added new macOS and Linux content and released ATT&CK for Containers. The Cloud domain benefitted from consolidation of the former AWS, Azure, and GCP platforms into a single IaaS (Infrastructure as a Service) platform. We updated ICS with cross-domain mappings and our infrastructure team introduced new ATT&CK Navigator elements to enhance your layer comparison and visualization experience. Finally, we added 8 new techniques, 27 sub-techniques, 24 new Group and over 100 new Software entries.
2022 Roadmap
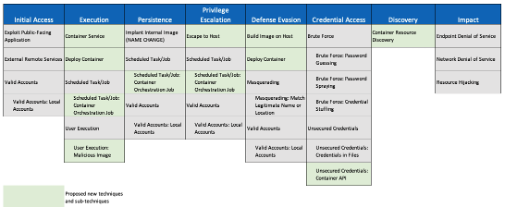
We have several exciting adjustments to the framework on the horizon for 2022, and while we will be making some structural changes this year (Mobile sub-techniques and the introduction of Campaigns), it won’t be nearly as painful as the addition of Enterprise sub-techniques in 2020. In addition to Campaigns and Mobile subs, our key adjustments this year include converting detections into objects, innovating how you can use overlays and combinations, and expanding ICS assets. We plan on maintaining the biannual release schedule of April and October, with a point release (v11.1) for Mobile sub-techniques.

ATT&CKcon 3.0 | March 2022
Your wait is finally over for ATT&CKCon, and we’re thrilled to be hosting it in McLean, VA on March 29–30. We welcome you to join the ATT&CK team and those across the community to hear about all the updates, insights, and creative ways organizations and individuals have been leveraging ATT&CK. We’ll be live streaming the full conference for free and you can find all of the latest details and updates on our ATT&CKcon 3.0 page.
Detection Objects | April & October 2022
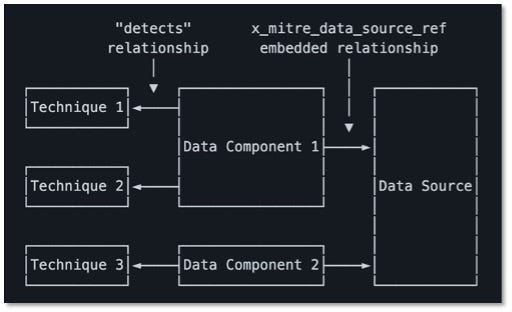
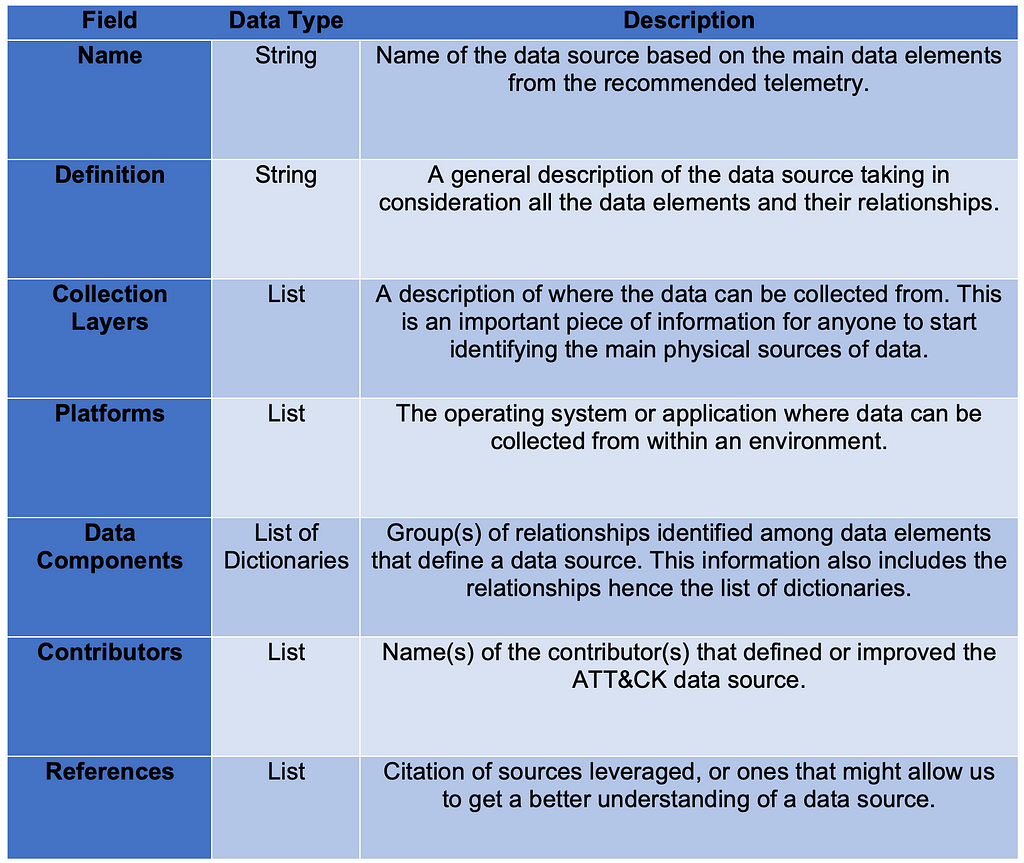
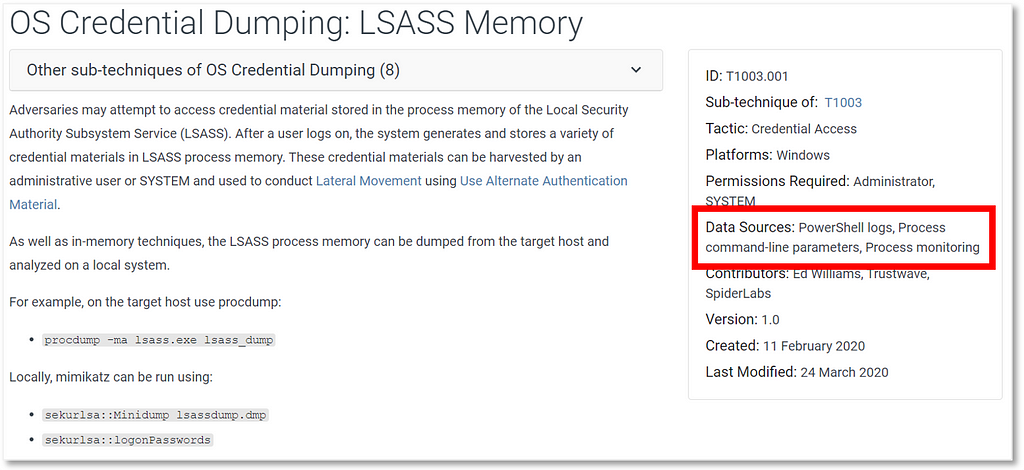
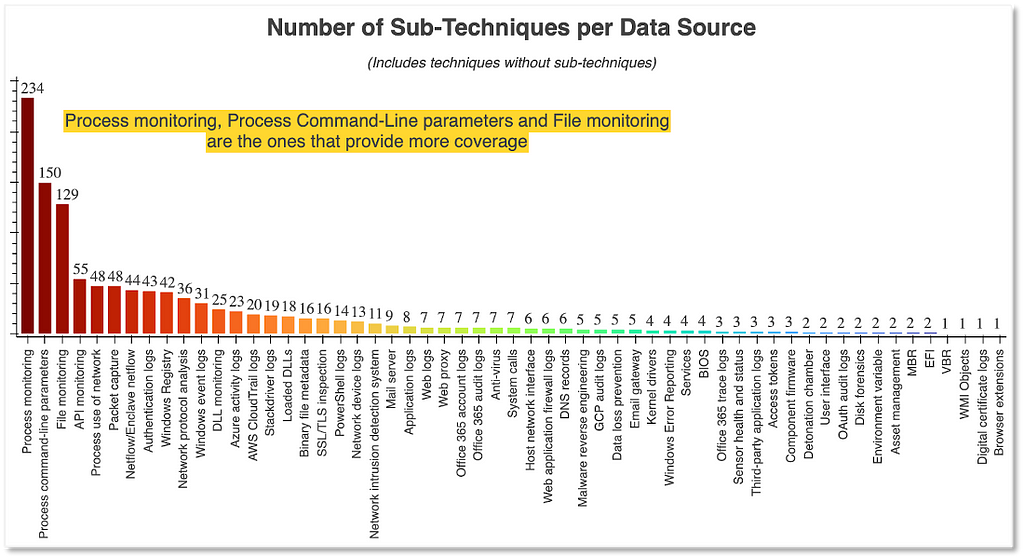
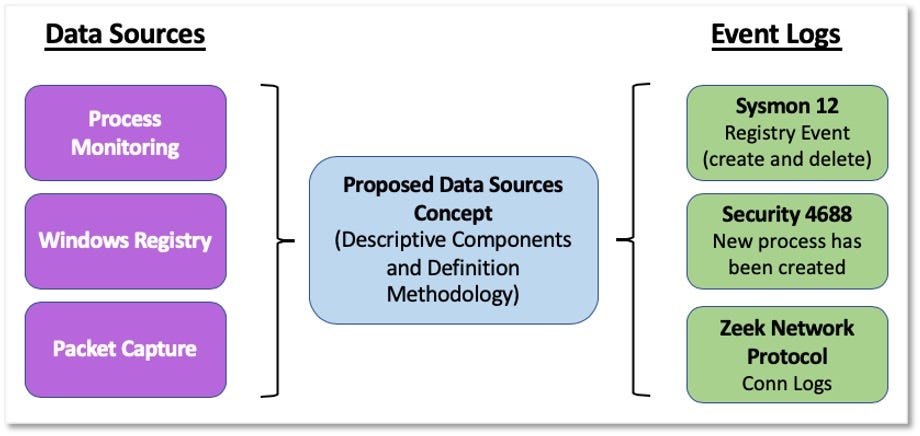
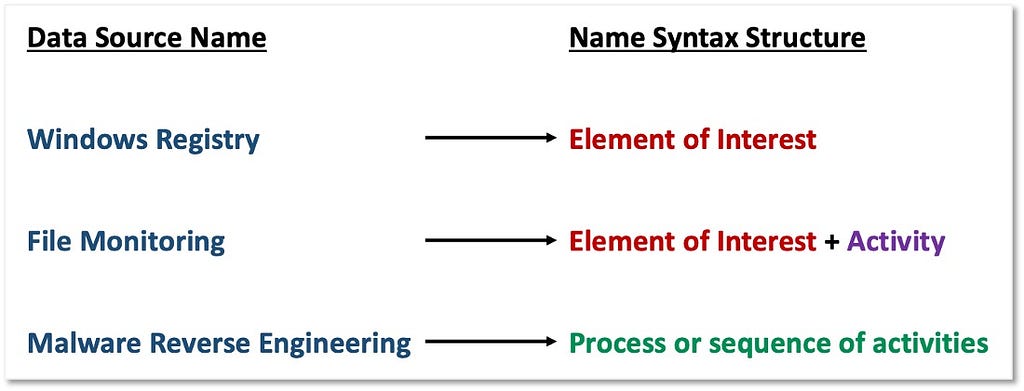
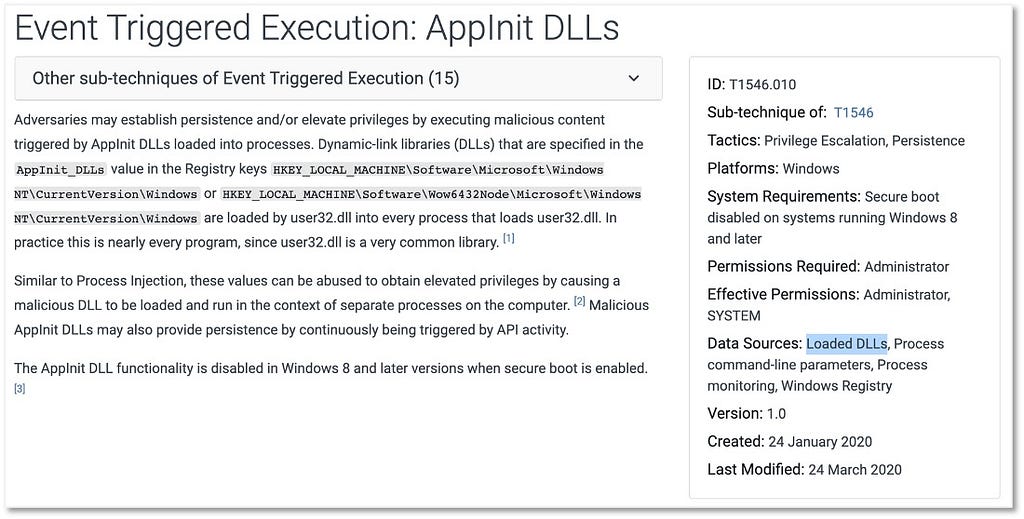
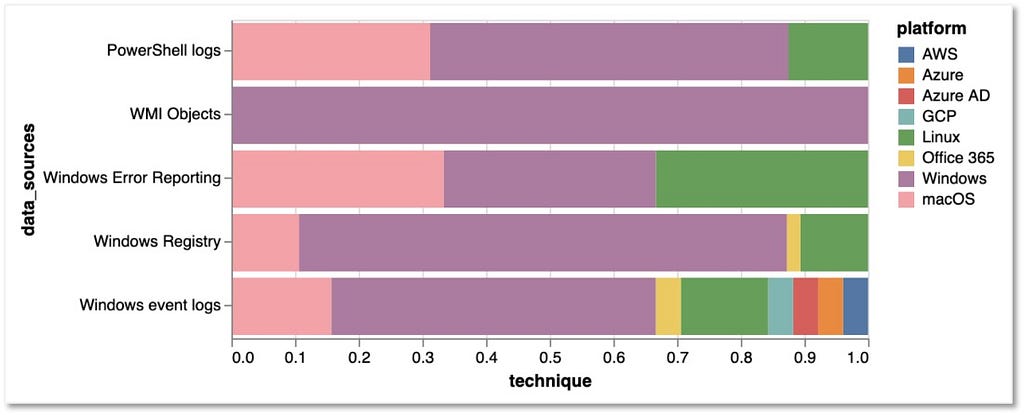
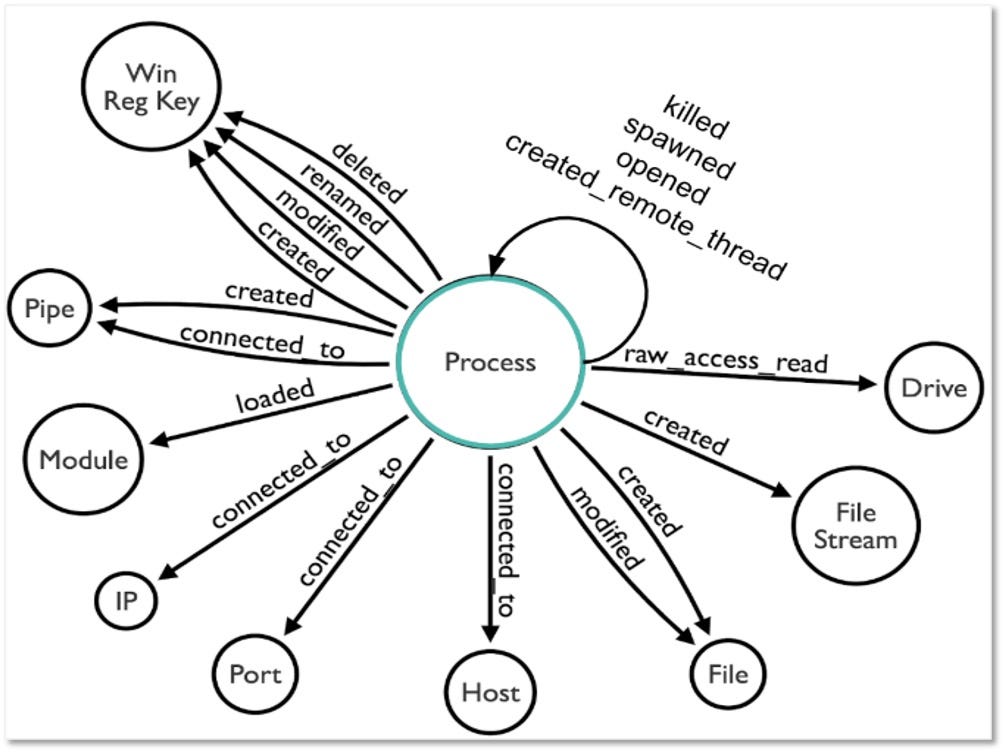
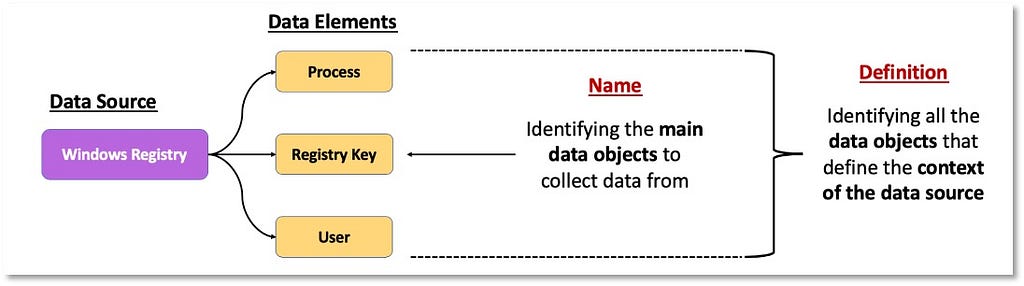
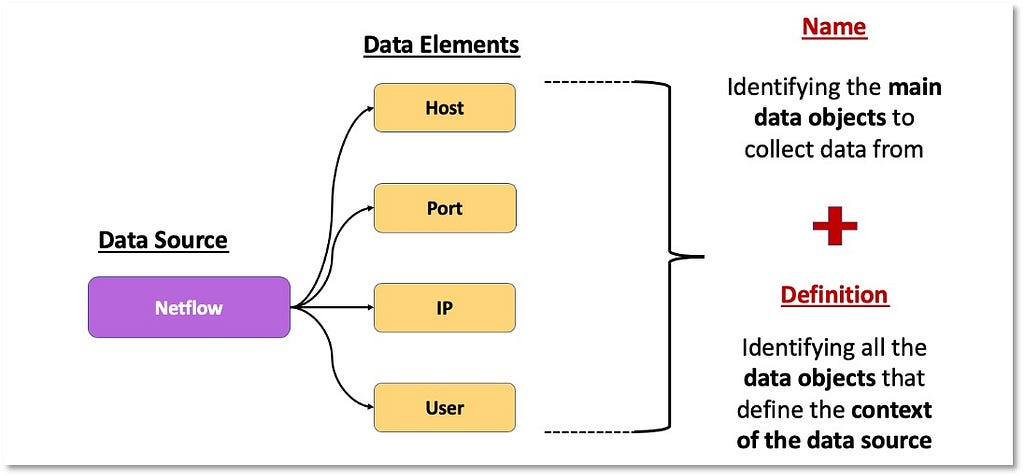
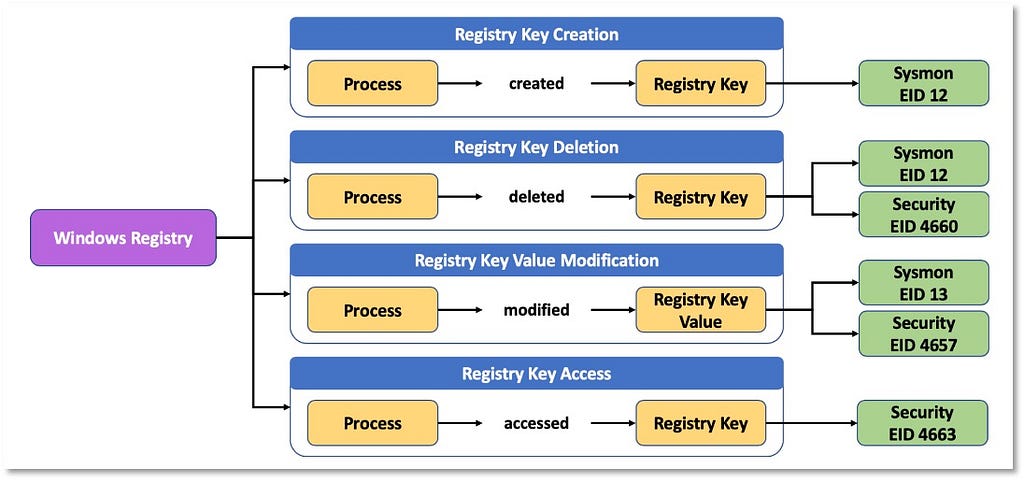
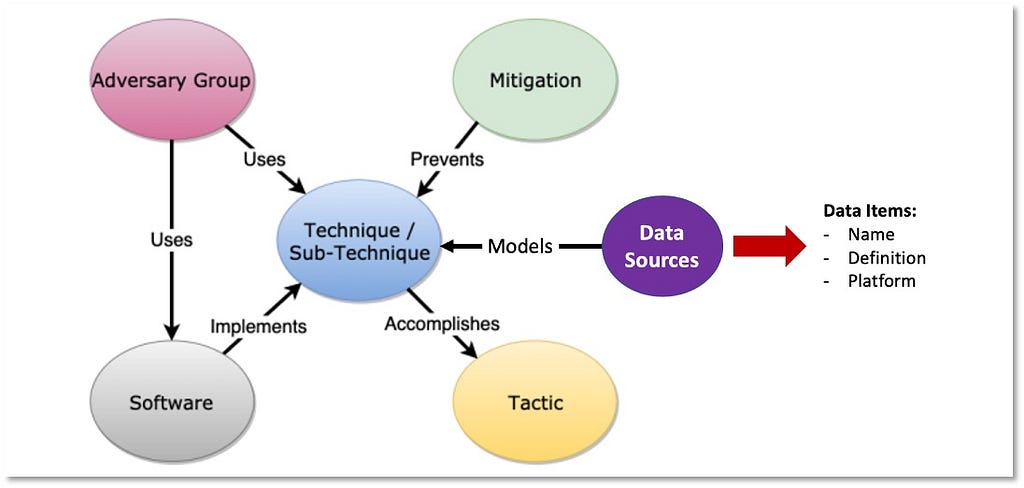
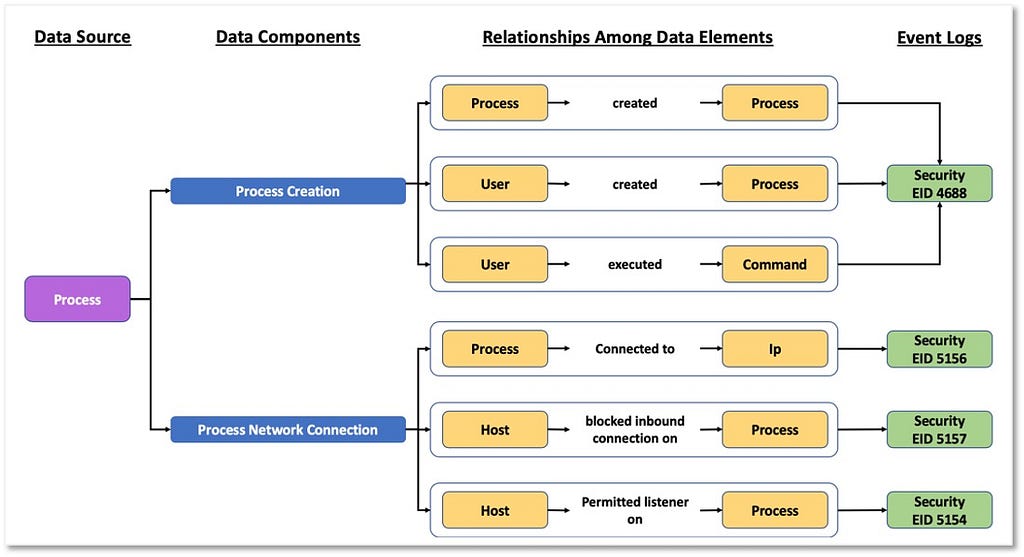
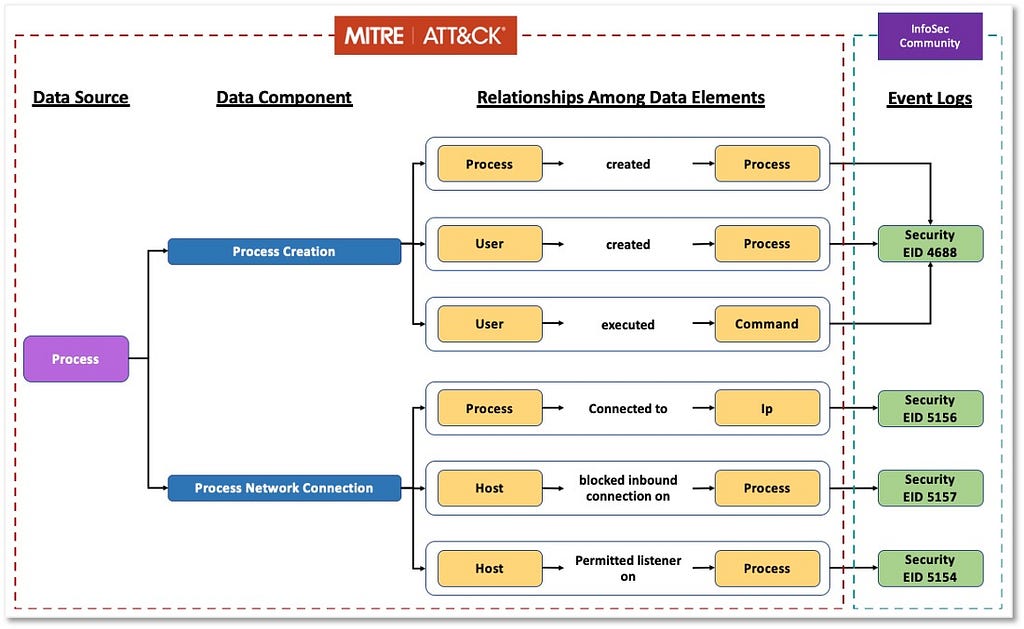
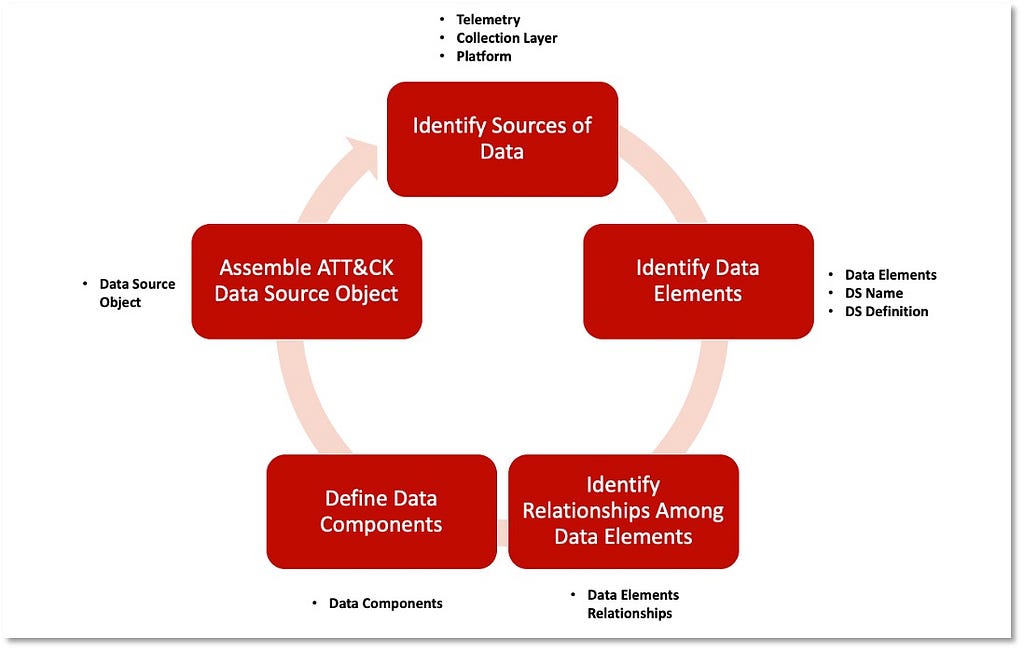
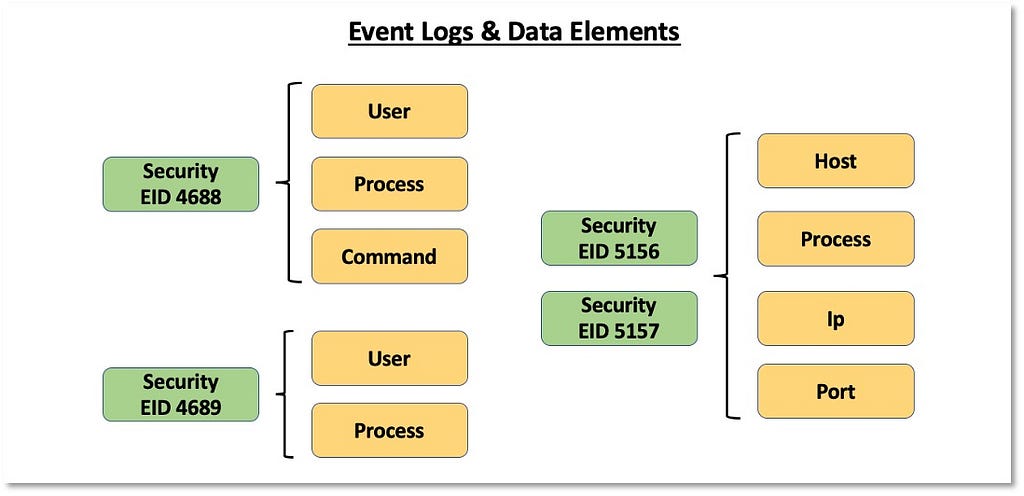
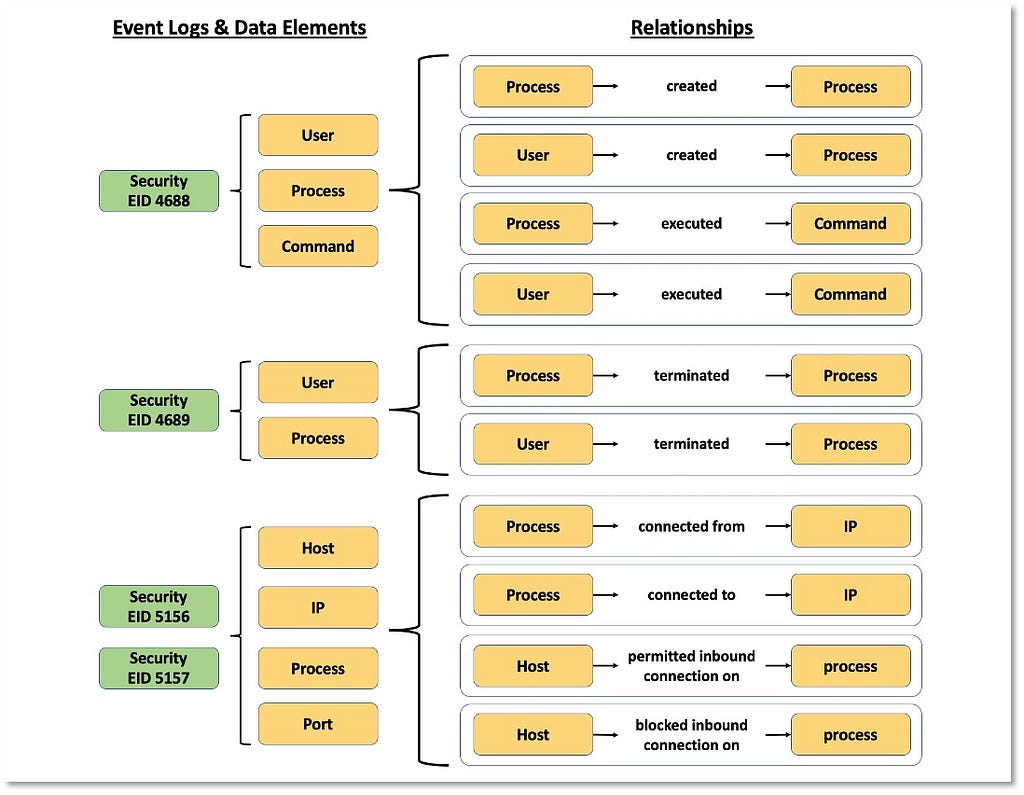
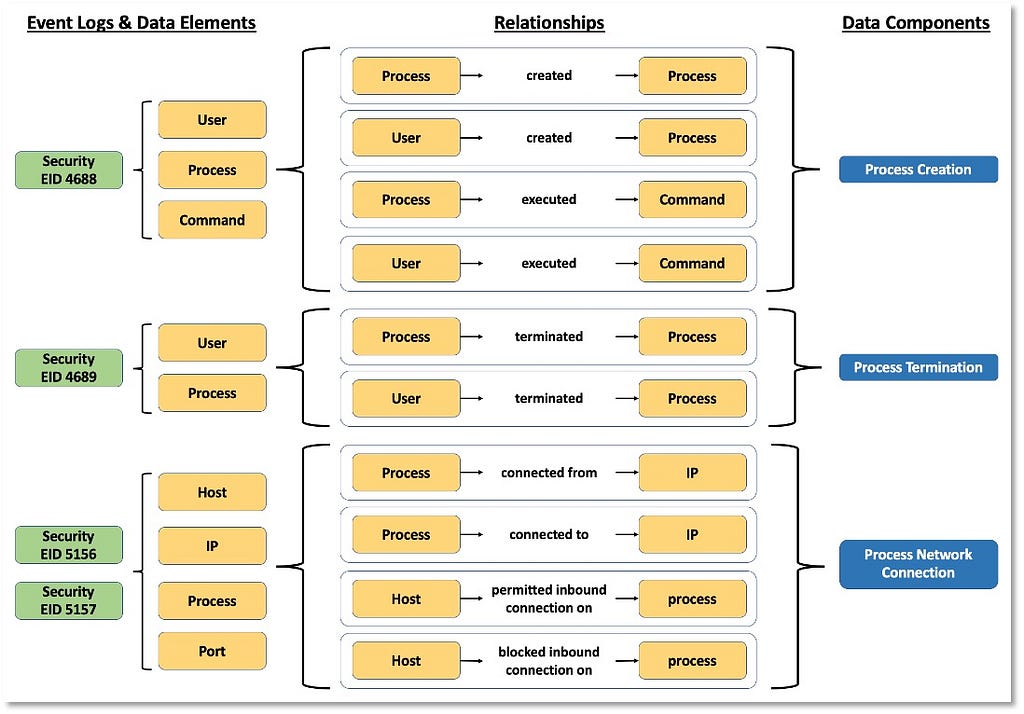
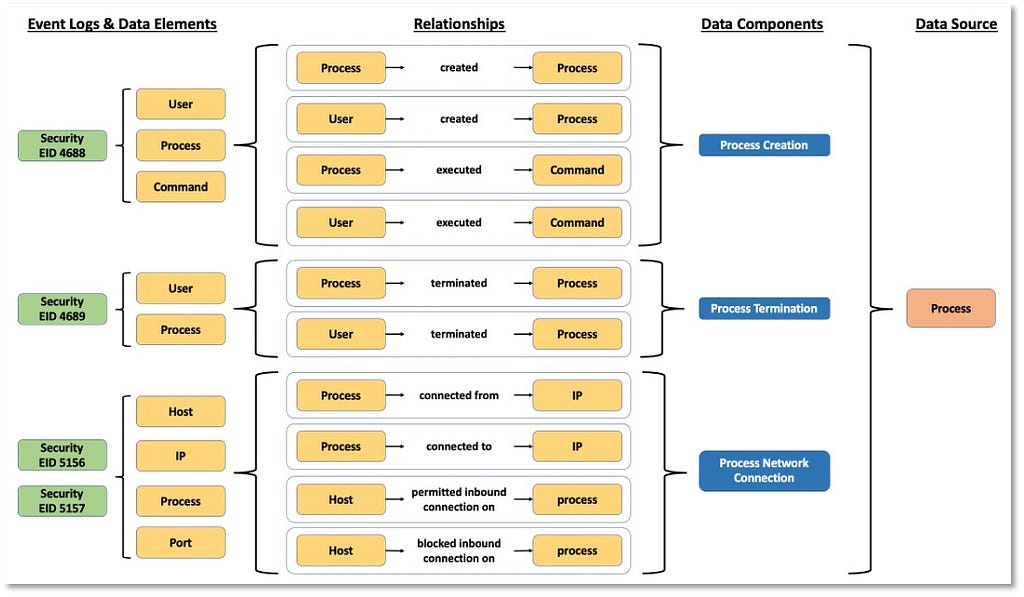
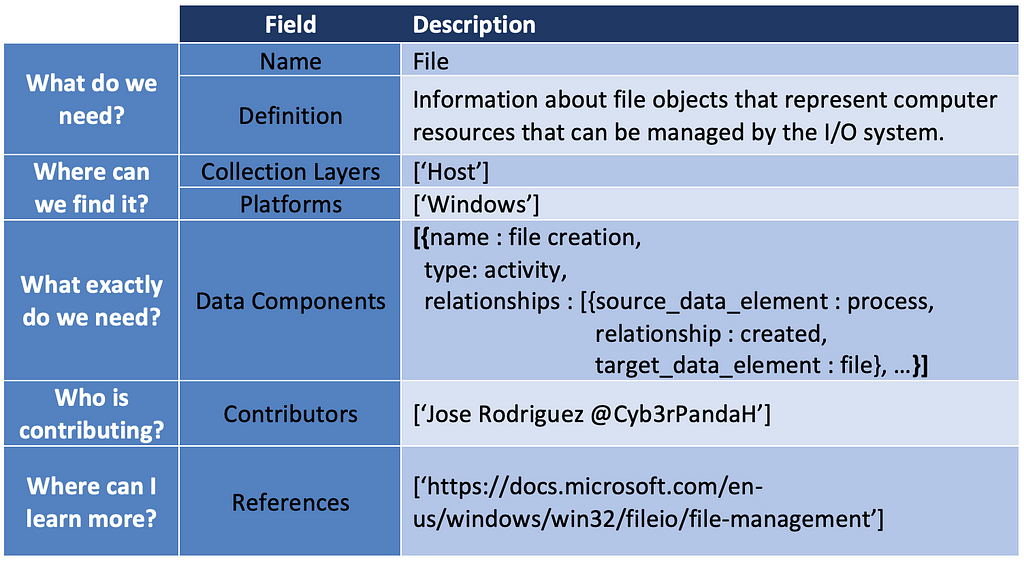
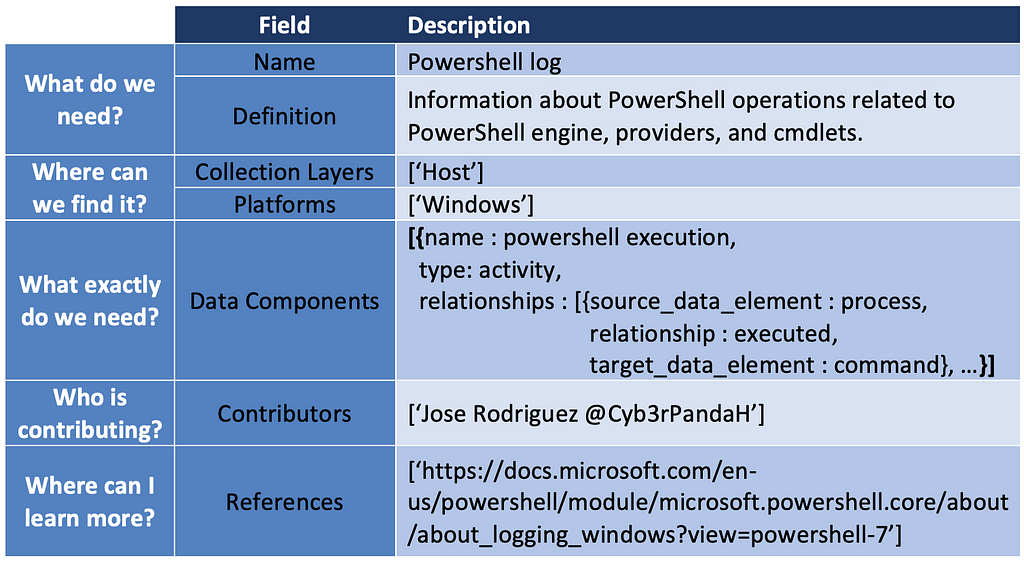
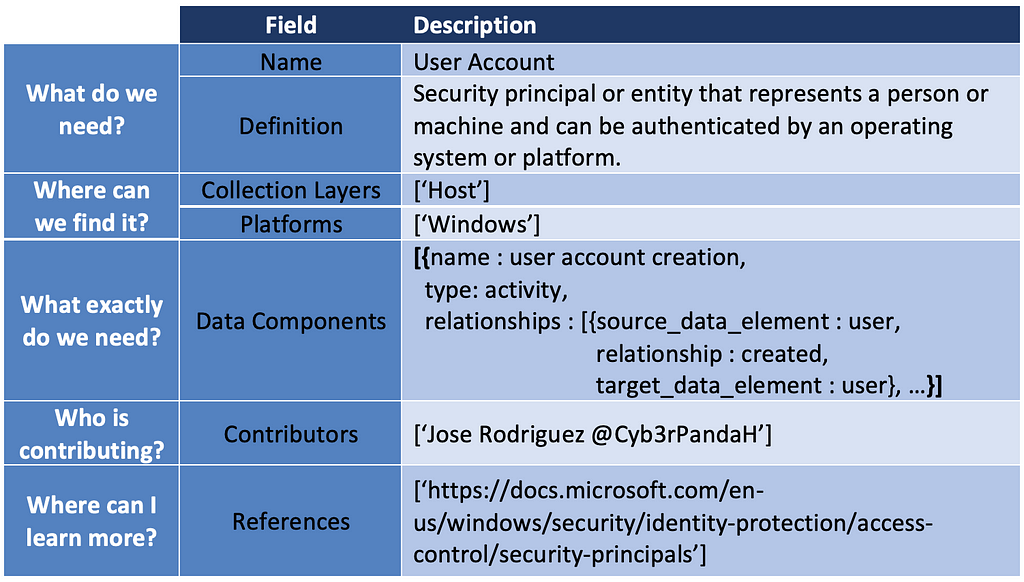
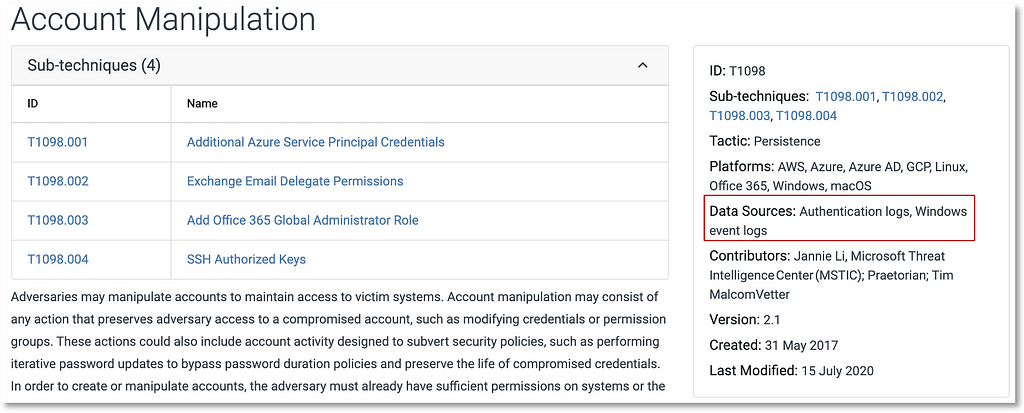
Over the past few years, transforming various actionable ATT&CK fields into managed objects has been a reoccurring theme. In v5 of ATT&CK, we converted mitigations into objects to enhance their value and usability — with this conversion, you can now identify a mitigation and pivot to various techniques it can potentially prevent. This has been a feature that many of you have leveraged to map ATT&CK to different control/risk frameworks. We also converted data sources to objects for the v10 release, enabling similar pivoting and analysis opportunities.
Next, we plan on implementing a parallel approach for detections, taking the currently free text featured in techniques, and refining and merging them into descriptions that are connected to data sources. This will enable us to describe for each technique what you need to collect as inputs for that detection (data sources), as well as how you could analyze that data to identify a given technique (detection).
Campaigns | October 2022
One of the more significant changes you can expect this year is the introduction of Campaigns. We define campaigns as a grouping of intrusion activity conducted over a specific period of time with common targets and objectives; this activity may or may not be linked to a specific threat actor. The Solar Winds cyber intrusion, for instance, would become a campaign attributed to the G0016 threat group in ATT&CK. In ATT&CK’s existing structure, all activity for a given threat actor is combined under a single Group entry, making it challenging to accurately see trends, understand how a threat actor has evolved over time (or not), identify the variance between different events, or, conversely, identify certain techniques that an actor may rely on.
In ATT&CK, we’ve never added activity as a Group that hasn’t been given a name by someone else. For example, if a report describes the behaviors of a group or campaign, but never gives that intrusion activity a unique name like FUZZYSNUGGLYDUCK/APT1337 (or links it to someone else’s reporting that does), we wouldn’t incorporate that report into ATT&CK. With the introduction of Campaigns we’ll start including reports that leave activity unnamed and use our own identifiers (watch out for Campaign C0001). On the flip side, this new structure will let us better manage activity where too many things have been given the same name (e.g., Lazarus), providing us a way to tease apart activity that shouldn’t have been grouped together. Finally, we’ll be able to better address intrusion activity where multiple threat actors may be involved, such are Ransomware-as-a-Service operations.
We’re still working to best determine how Campaigns and associated IDs will be displayed in ATT&CK and will provide additional detail in the coming months. Group and Software pages will mostly remain unchanged — they’ll still feature collective lists of techniques and sub-techniques so network defenders can continue to create overall associated Navigator layers and conduct similar analysis. However, we’ll be adding Campaign links to the associated Group/Software pages. We’ll be providing additional details later in the year, as we prepare to integrate Campaigns as part of the October release.
Mobile | April 2022
We’ve been talking about Mobile sub-techniques for a while, and we’re thrilled to say that they’re almost here. The Mobile team was hard at work in 2021, bringing ATT&CK for Mobile into feature equity with ATT&CK for Enterprise, including identifying where sub-techniques would fit into the Mobile matrix. As we covered in our October 2021 v10 release post, the Mobile sub-techniques will mirror the structure of the Enterprise sub-techniques to address granularity levels. We’ll be including a beta version of the sub-techniques, similar to what we did with Enterprise, for community feedback as part of the April ATT&CK v11 release. We plan on publishing the finalized sub-techniques in a point release (e.g., v11.1), and we’ll include more details about the subs process and timeline in our April release post. In addition to sub-techniques, we’ll be working on a concept for Mobile data source objects, and reigniting our mini-series highlighting significant threats to mobile devices that we kicked off last year. As always, we remain very interested in adversary behavior targeting mobile devices, so if you would like to help us create new techniques, or if you have observed behaviors you’d like to share, reach out to us.
Finally, stay tuned for the ATT&CK for Mobile 2022 Roadmap that will be arriving soon. While we don’t typically publish separate roadmaps for technology domains, Mobile needs some additional space this year to cover the updates and planned content changes.
MacOS and Linux | April & October 2022
We made many adjustments, additions, and content updates to the macOS and Linux platforms last year, with a focus on macOS. For 2022 we hope to maintain the macOS momentum while transitioning our focus to updating Linux. Our April release will center around resolving several macOS contributions from last year. These updates include broadening the scope of parent techniques to include additional platforms, adding sub-techniques, updating procedures with specific usage examples, and supporting the data sources + detection efforts. We will continue to update macOS throughout the year and greatly appreciate the community engagement and all of the contributors that have enabled us to better represent this platform.
The April release will also feature revised language and platform mapping for Linux. We’re aiming for an improved representation of Linux within ATT&CK for all techniques by our October release. Although Linux is frequently leveraged by adversaries, public reporting is often scarce on detail making this a challenging platform for ATT&CK. Our ability to describe this space is closely tied to those of you in the Linux security community, and we hope to engage and establish more connections with you over the next several months. If you’re interested in sharing any observed activities or suggestions for techniques, please reach out and let us know.
ICS | October 2022
We updated our ICS content and data sources in 2021, and over the next several months, we’ll be expanding ICS Assets and adding detections. Asset names are tied to specific ICS verticals (e.g., electric power, water treatment, manufacturing), and the associated technique mappings enable users to understand if and how techniques apply to their environments. In addition, more granular asset definitions will help to highlight similarities and differences in functionality across technologies and verticals. The detections we’ll be adding to each technique will provide guidance on how the recently updated data sources can be used to identify adversary behavior. Finally, we’re preparing to integrate ICS onto the same platform as Enterprise and join the rest of the domains on the ATT&CK website (attack.mitre.org) later this year.
Overlays and Combinations | October 2022
Throughout the next several months, we’ll continue moving towards developing and sharing ideas for overlays and combinations, or how you can pull various ATT&CK platforms and domains together into a specialized view of ATT&CK. Using Linux and Containers together, for example, or integrating security across Enterprise and Mobile, or between Enterprise and ICS. Our goal with this effort is to provide the tools and resources for the community to leverage the various spaces of ATT&CK, and tailor them to their security needs.
Connect With Us!
ATT&CK will always be community-driven and our continued impact hinges on our collaboration with all of you. Your on-the-ground experience and input enables us to continue to evolve and we look forward to connecting with you on email, Twitter, or Slack.
ATT&CK 2022 Roadmap was originally published in MITRE ATT&CK® on Medium, where people are continuing the conversation by highlighting and responding to this story.