
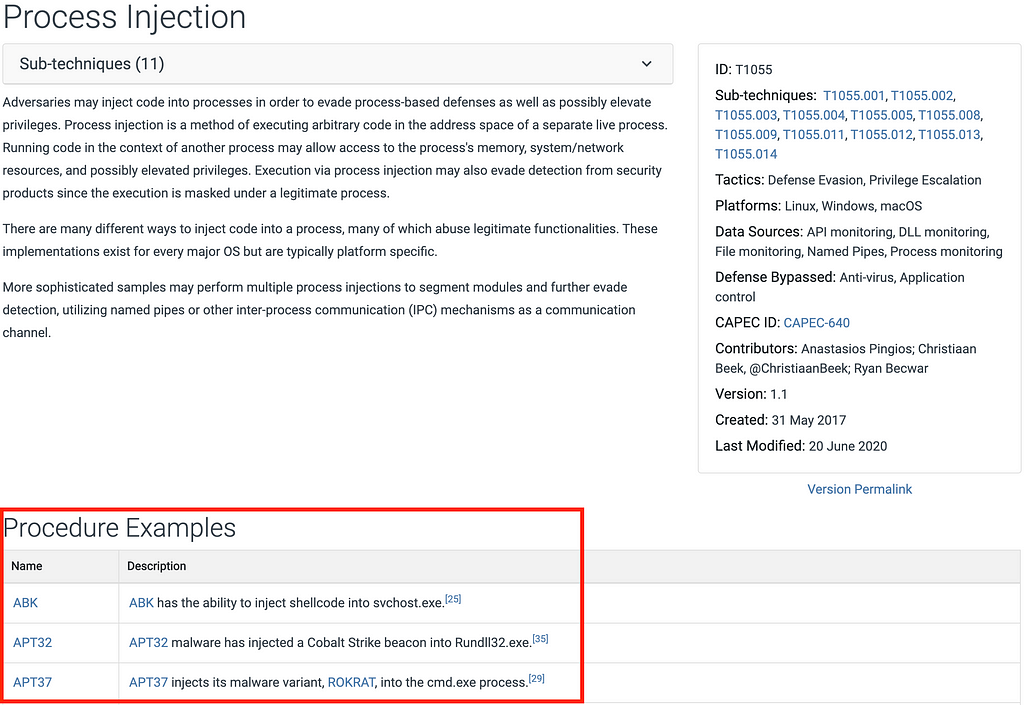
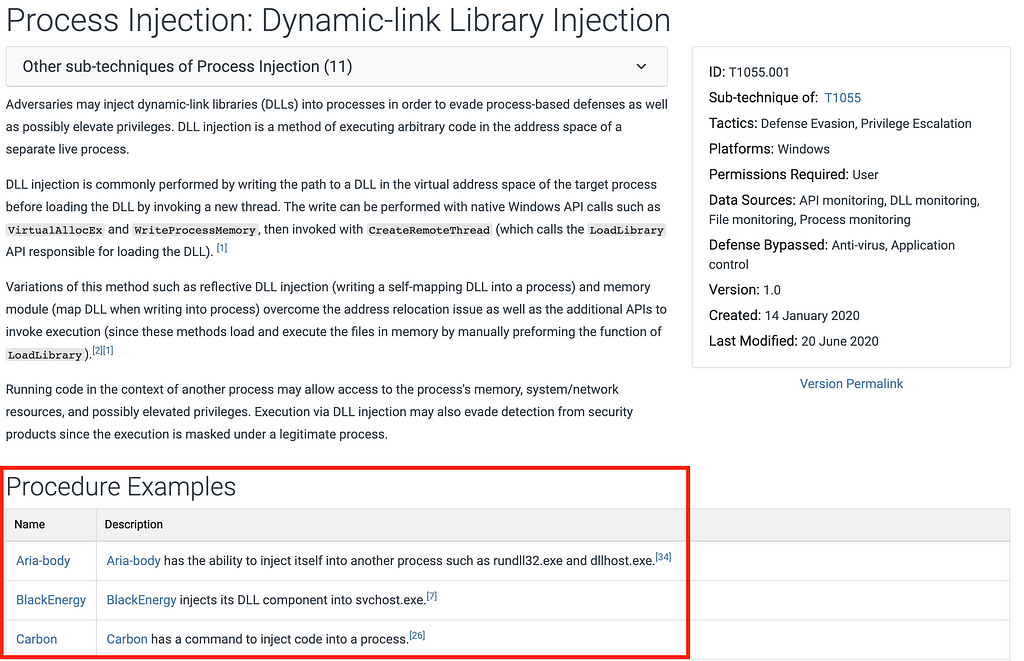
Defining ATT&CK Data Sources, Part II: Operationalizing the Methodology

In Part I of this two-part blog series, we reviewed the current state of the data sources and an initial approach to enhancing them through data modeling. We also defined what an ATT&CK data source object represents and extended it to introduce the concept of data components.
In Part II, we’ll explore a methodology to help define new ATT&CK data source objects, how to implement the methodology with current data sources, and share an initial set of data source objects at https://github.com/mitre-attack/attack-datasources.
Formalizing the Methodology
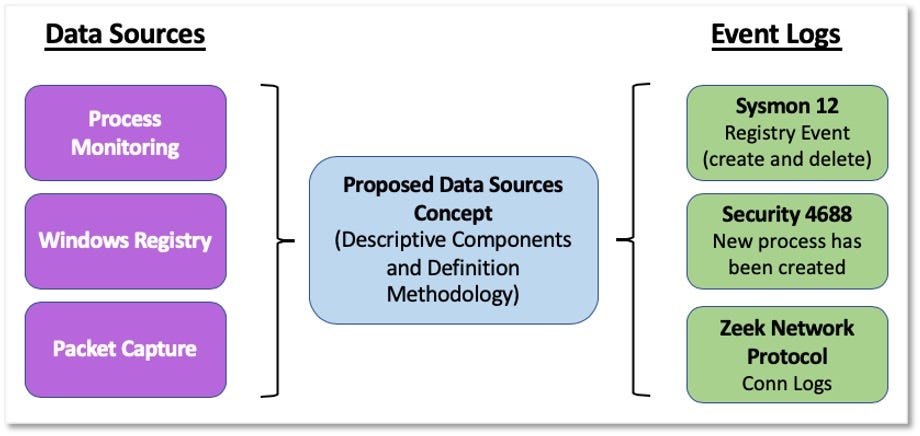
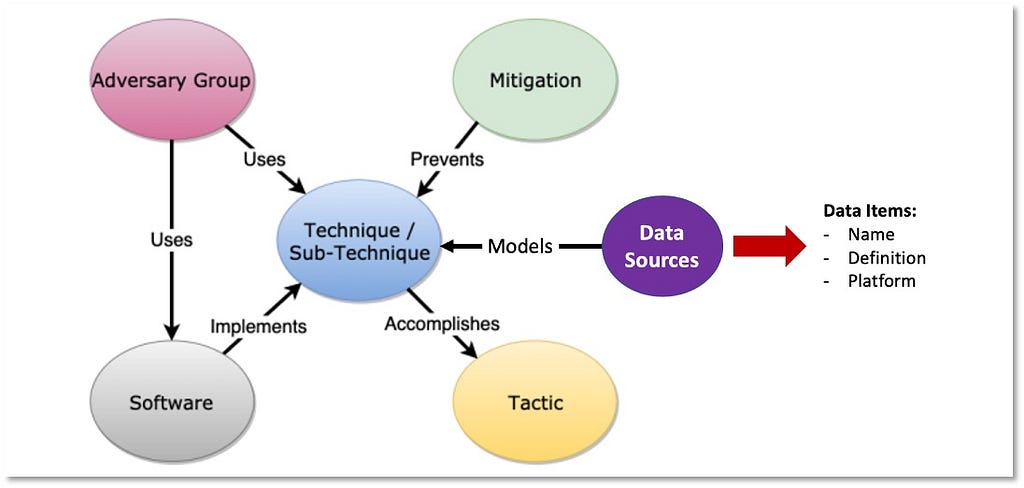
In Part I we proposed defining data sources as objects within the ATT&CK framework and developing a standardized approach to name and define data sources through data modeling concepts. Our methodology to accomplish this objective is captured in five key steps — Identify Sources of Data, Identify Data Elements, Identify Relationships Among Data Elements, Define Data Components, and Assemble the ATT&CK Data Source Object.
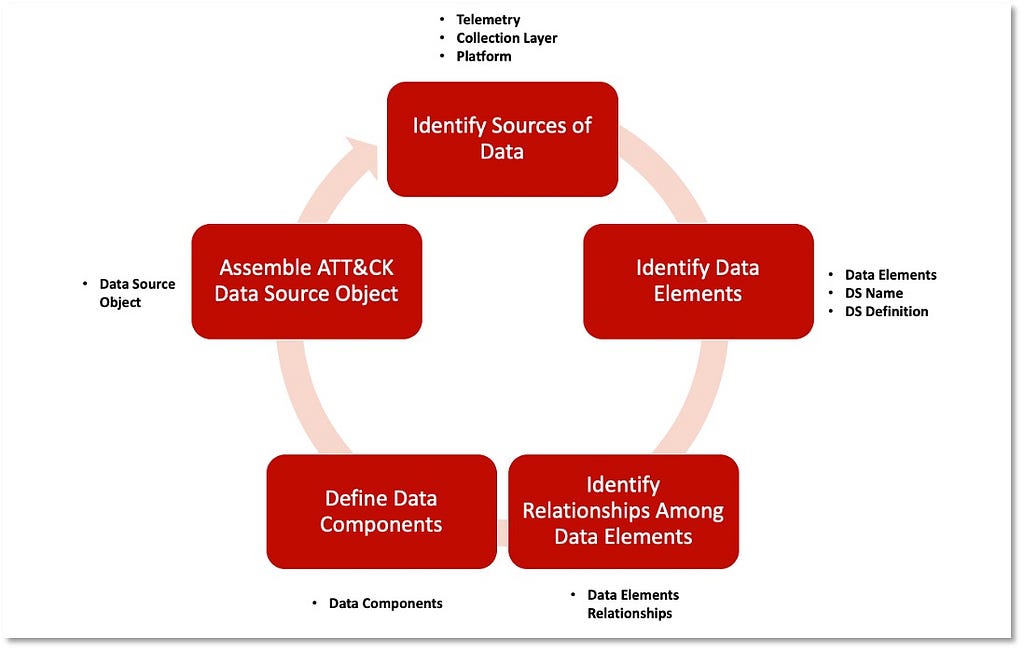
Step 1: Identify Sources of Data
Identifying the security events to inform the specific ATT&CK data sources being assessed kickstarts the process. The security events can be uncovered by reviewing the metadata in the event logs that reference the specific data source (i.e., process name, process path, application, image). We recommend complementing this step with documentation or data dictionaries that identify relevant event logs to provide the key context around the data source. It’s important at this phase in the process to document where the data can be collected (collection layer and platform).
Step 2: Identify Data Elements
Extracting data elements found in the available data enables identification of the data elements that could provide the name and the definition of the data source.
Step 3: Identify Relationships Among Data Elements
During the identification of data elements, we can also start documenting the available relationships that will be grouped to enable us to define potential data components.
Step 4: Define Data Components
The output of grouping the relationships is a list of all potential data components that could provide additional context to the data source.
Step 5: Assemble the ATT&CK Data Source Object
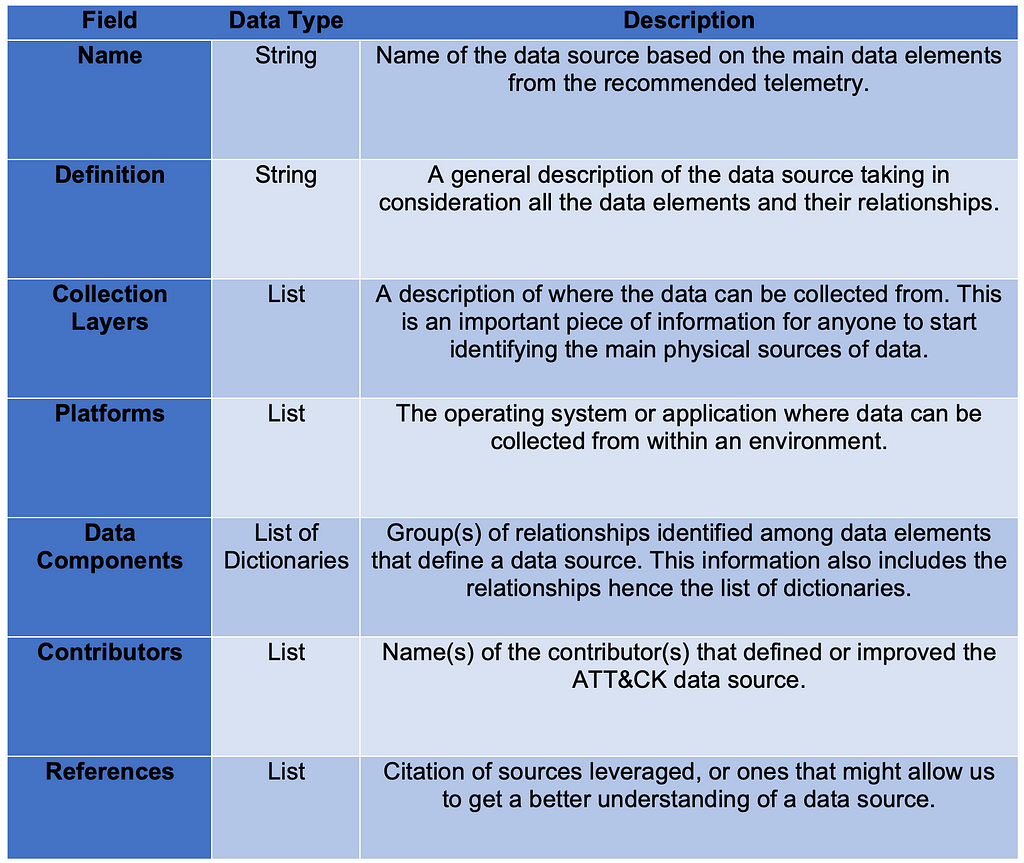
Connecting all of the information from previous steps enables us to structure them as properties of the data source object. The table below provides an approach for organizing the combined information into a data source object.
Operationalizing the Methodology
To illustrate how the methodology can be applied to ATT&CK data sources, we feature use cases in the following sections that reflect and operationalize the process.
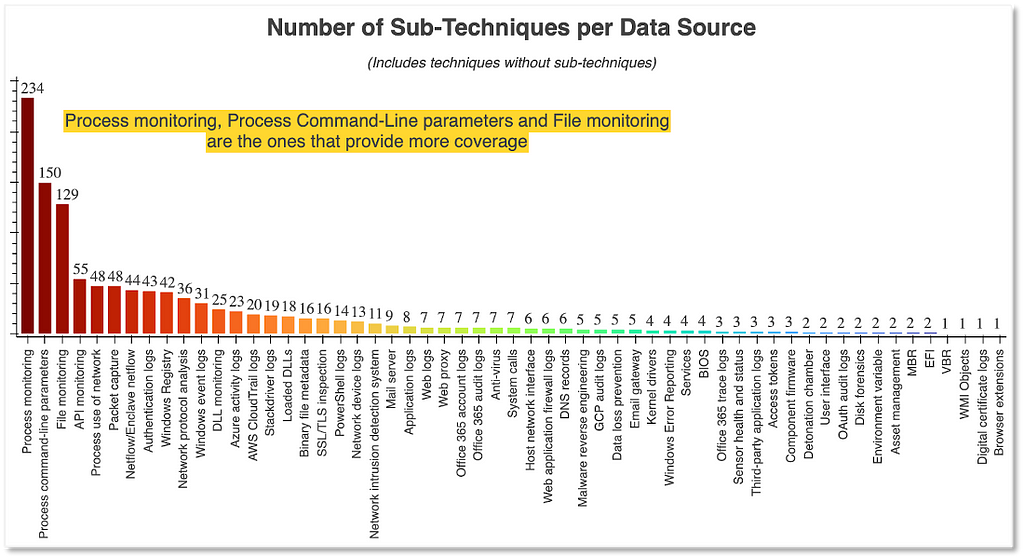
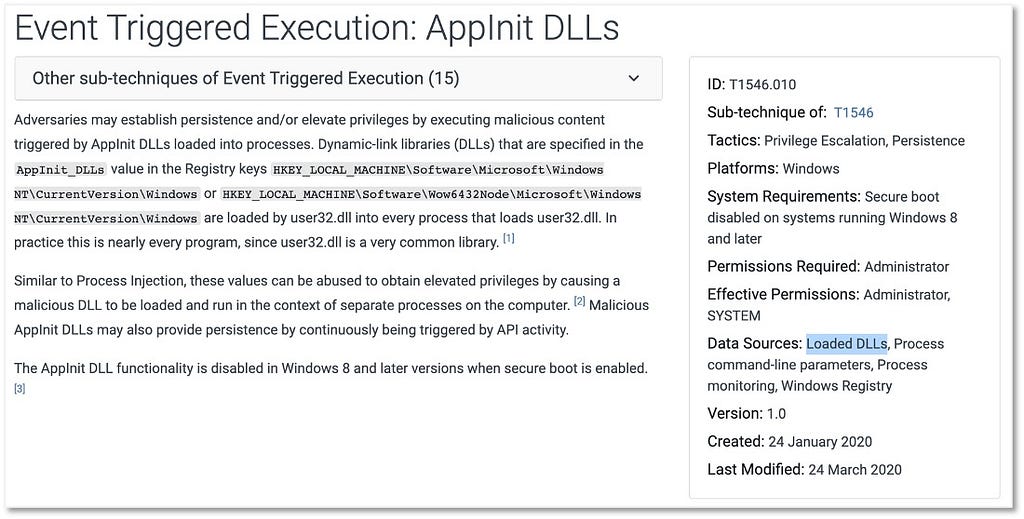
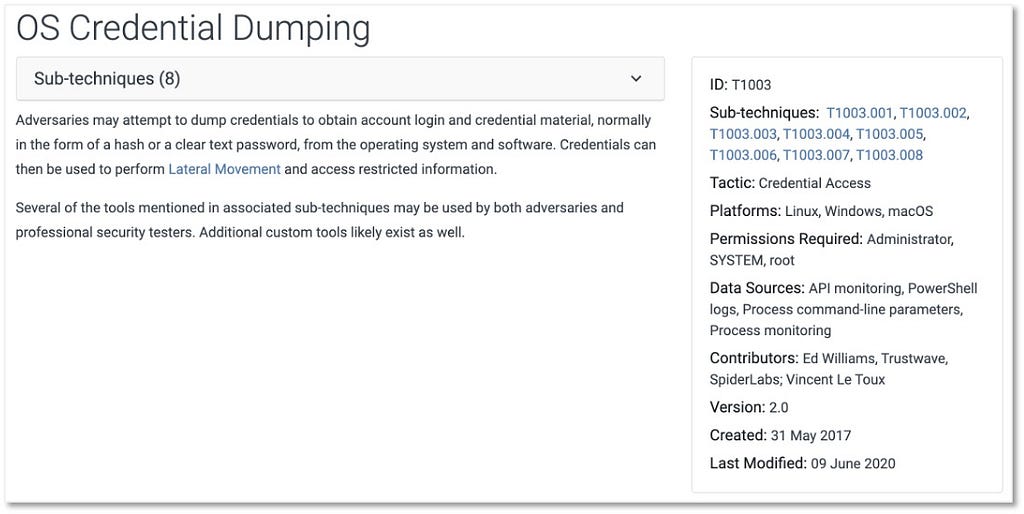
Starting with the ATT&CK data source that is mapped to the most sub-techniques in the framework, Process Monitoring, we will create our first ATT&CK data source object. Next we will create another ATT&CK data source object around Windows Event Logs, a data source that is key for detecting a significant number of techniques
Windows is leveraged for the use cases, but the approach can and should be applied to other platforms.
Improving Process Monitoring
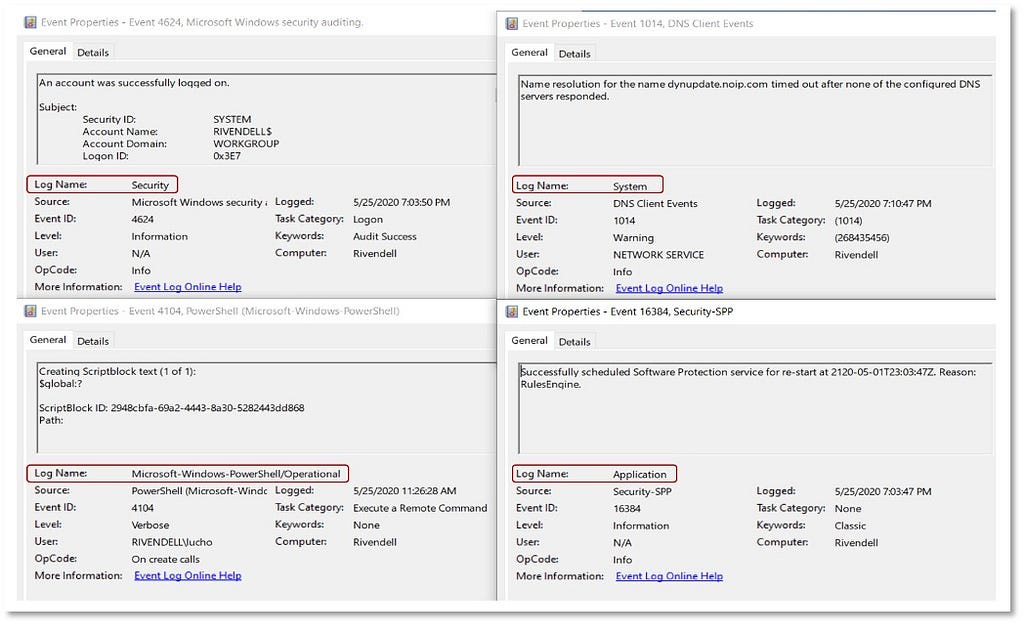
1) Identifying Sources of Data: In a Windows environment, we can collect information pertaining to “Processes” from built-in event providers such as Microsoft-Windows-Security-Auditing and open third-party tools, including Sysmon.
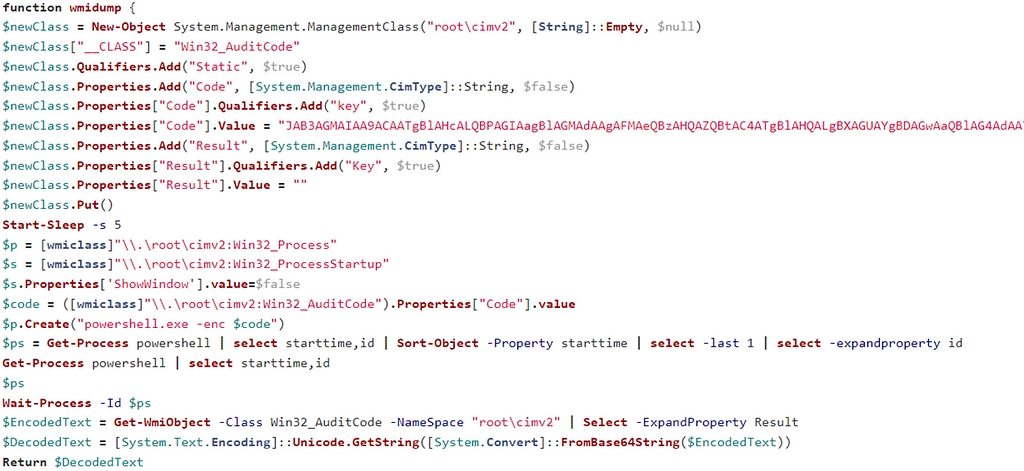
This step also takes into account the overall security events where a process can be represented as the main data element around an adversary action. This could include actions such as a process connecting to an IP address, modifying a registry, or creating a file. The following image displays security events from the Microsoft-Windows-Security-Auditing provider and the associated context about a process performing an action on an endpoint:

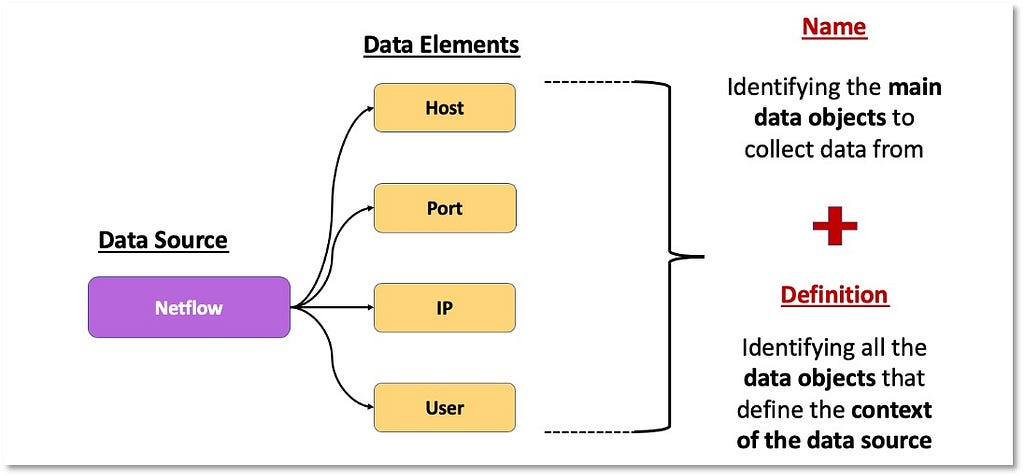
These security events also provide information about other data elements such as “User”, “Port” or “Ip”. This means that security events can be mapped to other data elements depending on the data source and the adversary (sub-)technique.
The source identification process should leverage available documentation about organization-internal security events. We recommend using documentation about your data or examining data source information in open source projects such as DeTT&CT, the Open Source Security Events Metadata (OSSEM), or ATTACK Datamap.
An additional element that we can extract from this step is the data collection location. A simple approach for identifying this information includes documenting the collection layer and platform for the data source:
- Collection Layer: Host
- Platform: Windows
The most effective data collection strategy will be customized to your unique environment. From a collection layer standpoint, this varies depending on how you collect data in your environment, but Process information is generally collected directly from the endpoint. From a platform perspective, this approach can be replicated on other platforms (e.g., Linux, macOS, Android) with the corresponding data collection locations captured.
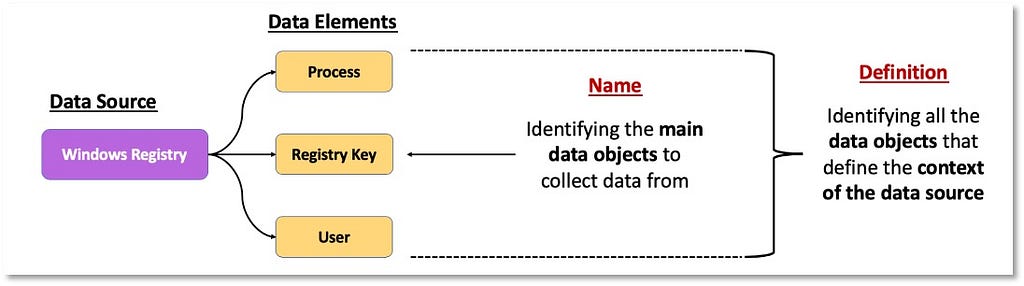
2) Identifying Data Elements: Once we identify and understand more about sources of data that can be mapped to an ATT&CK data source, we can start identifying data elements within the data fields that could help us eventually represent adversary behavior from a data perspective. The image below displays how we can extend the concept of an event log and capture the data elements featured within it.
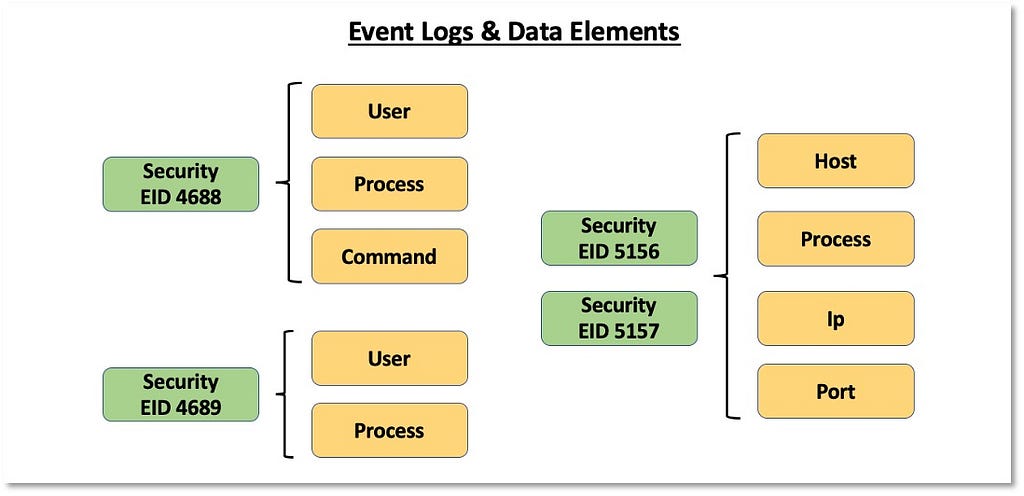
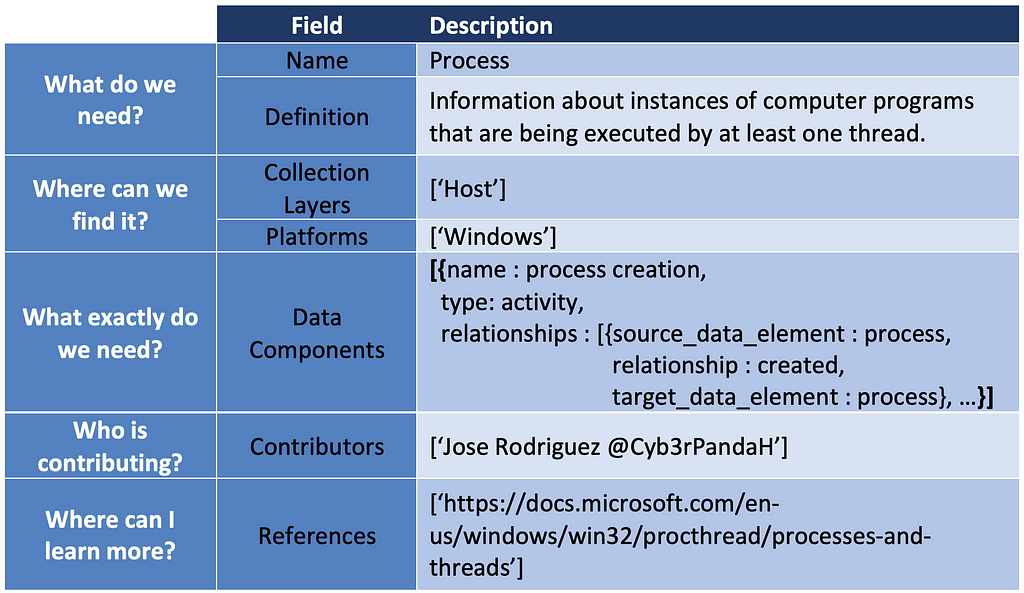
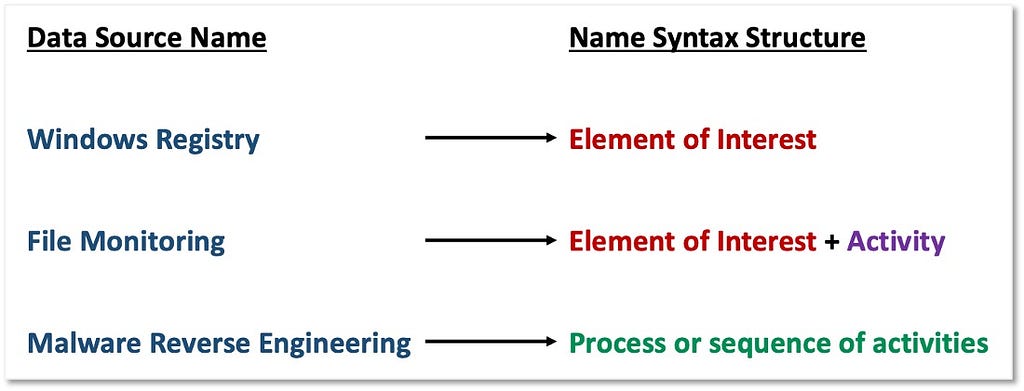
We will also use the data elements identified within the data fields to create and improve the naming of data sources and inform the data source definition. Data source designations are represented by the core data element(s). In the case of Process Monitoring, it makes sense for the data source name to contain “Process” but not “Monitoring,” as monitoring is an activity around the data source that is performed by the organization. Our naming and definition adjustments for “Process” are featured below:
- Name: Process
- Definition: Information about instances of computer programs that are being executed by at least one thread.
We can leverage this approach across ATT&CK to strategically remove extraneous wording in data sources.
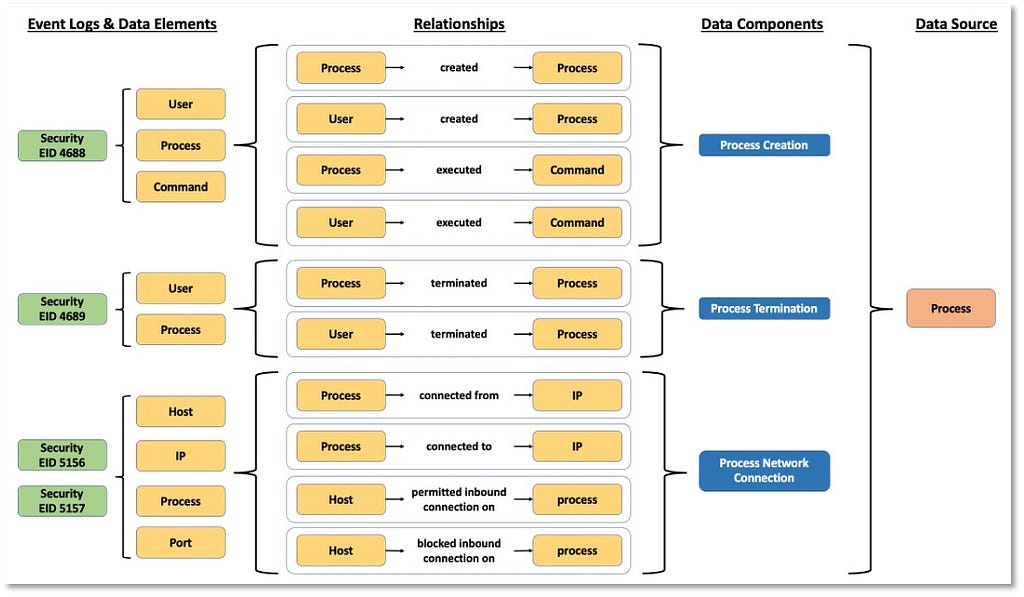
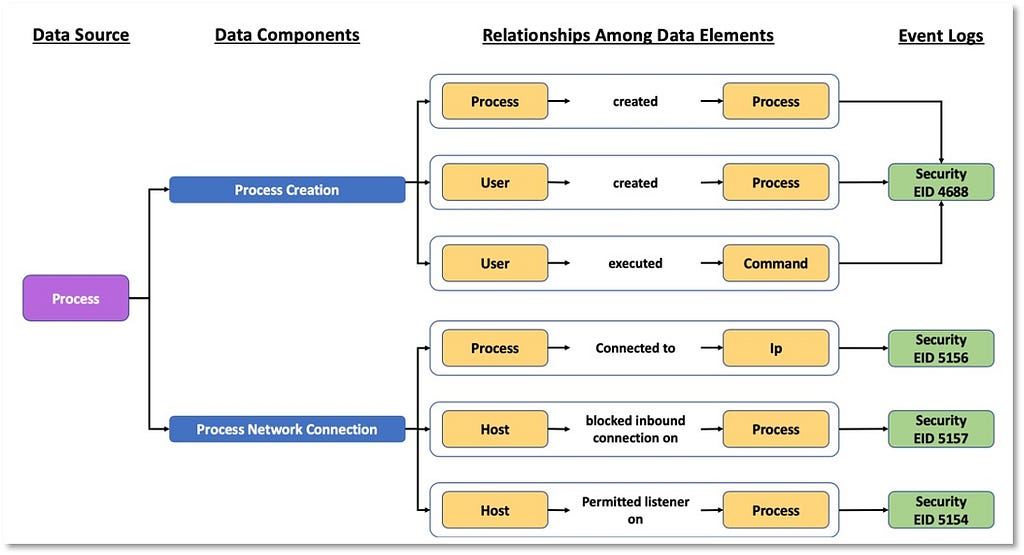
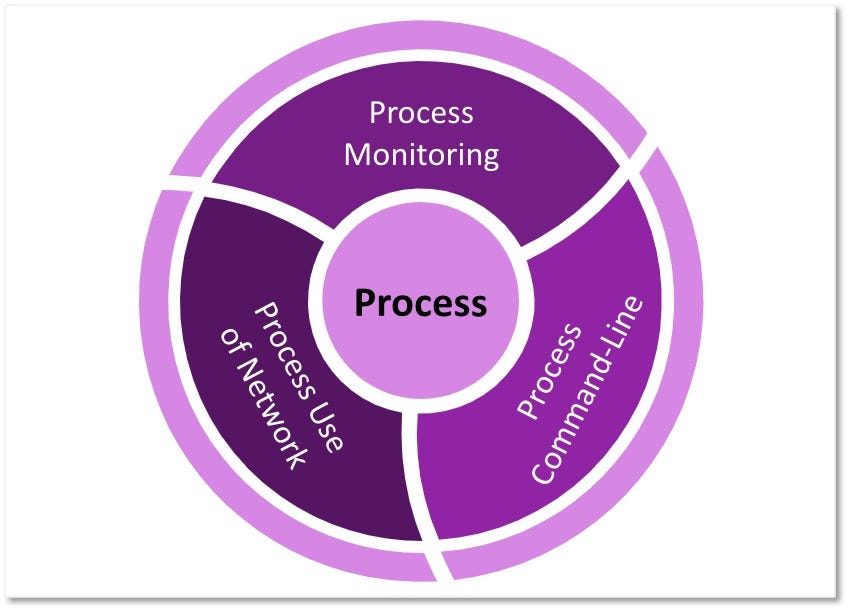
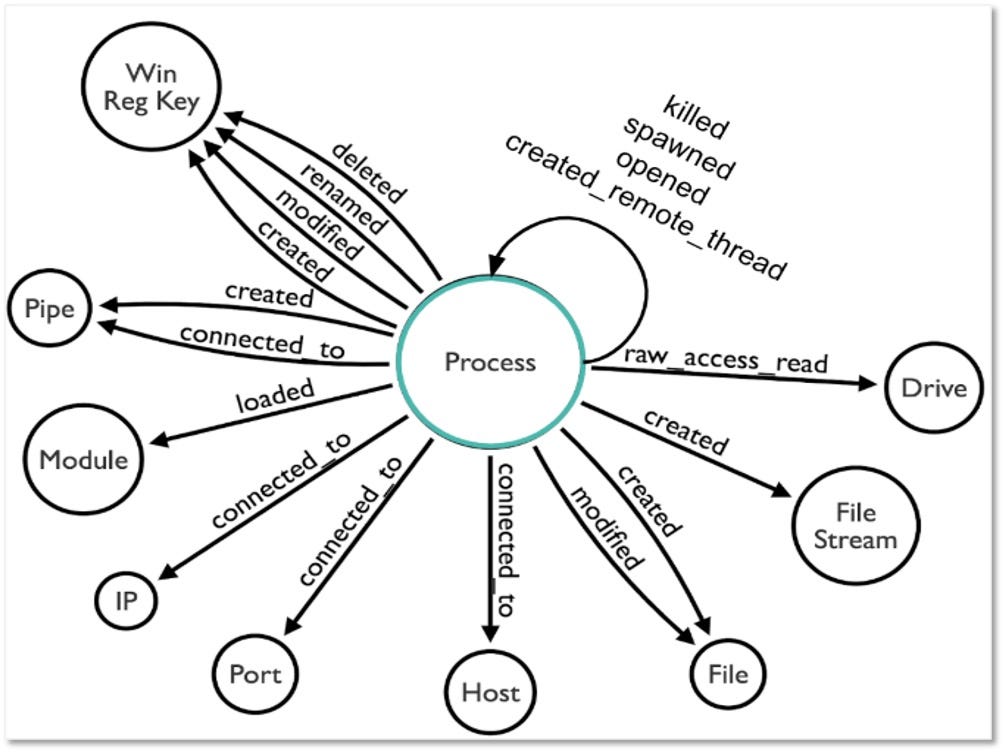
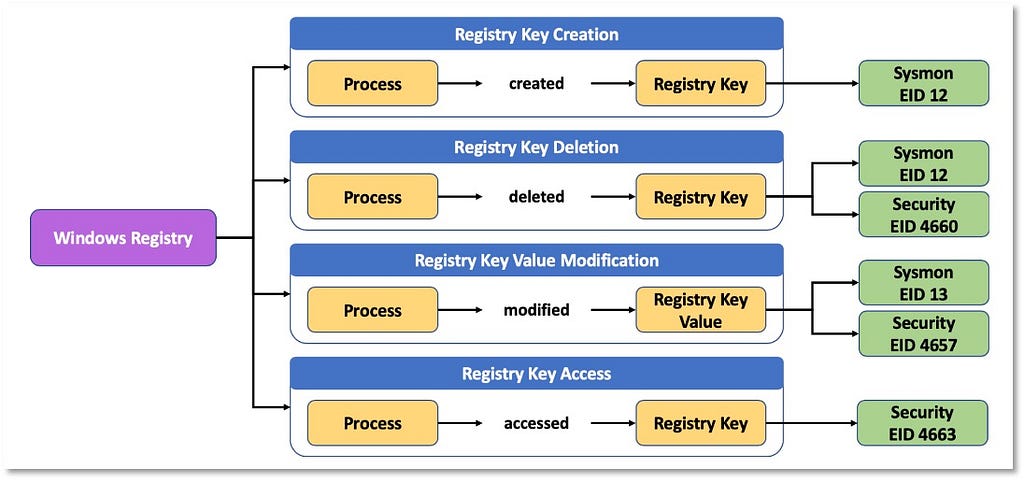
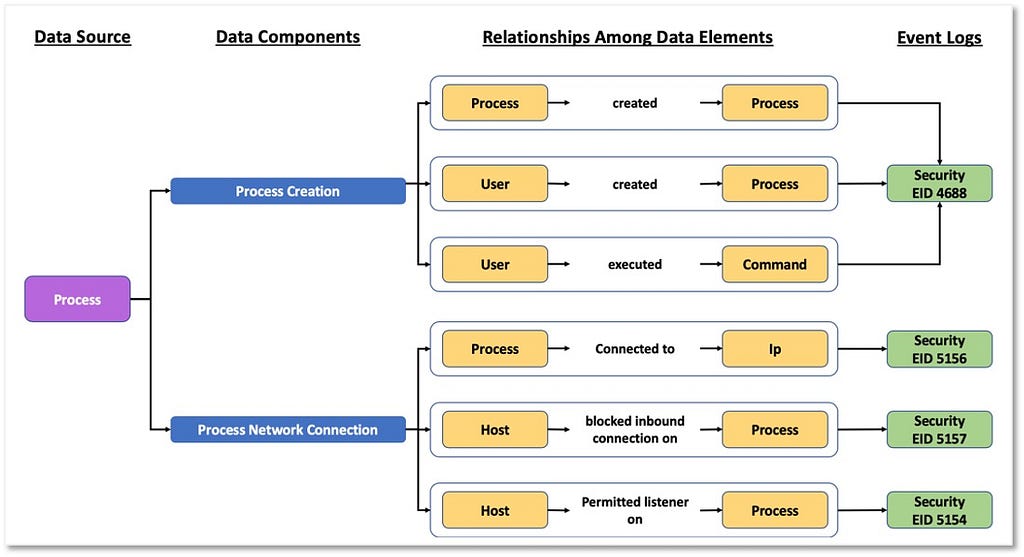
3) Identifying Relationships Among Data Elements: Once we have a better understanding of the data elements and a more relevant definition for the data source itself, we can start extending the data elements information and identifying relationships that exist among them. These relationships can be defined based on the activity described by the collected telemetry. The following image features relationships identified in the security events that are related to the “Process” data source.
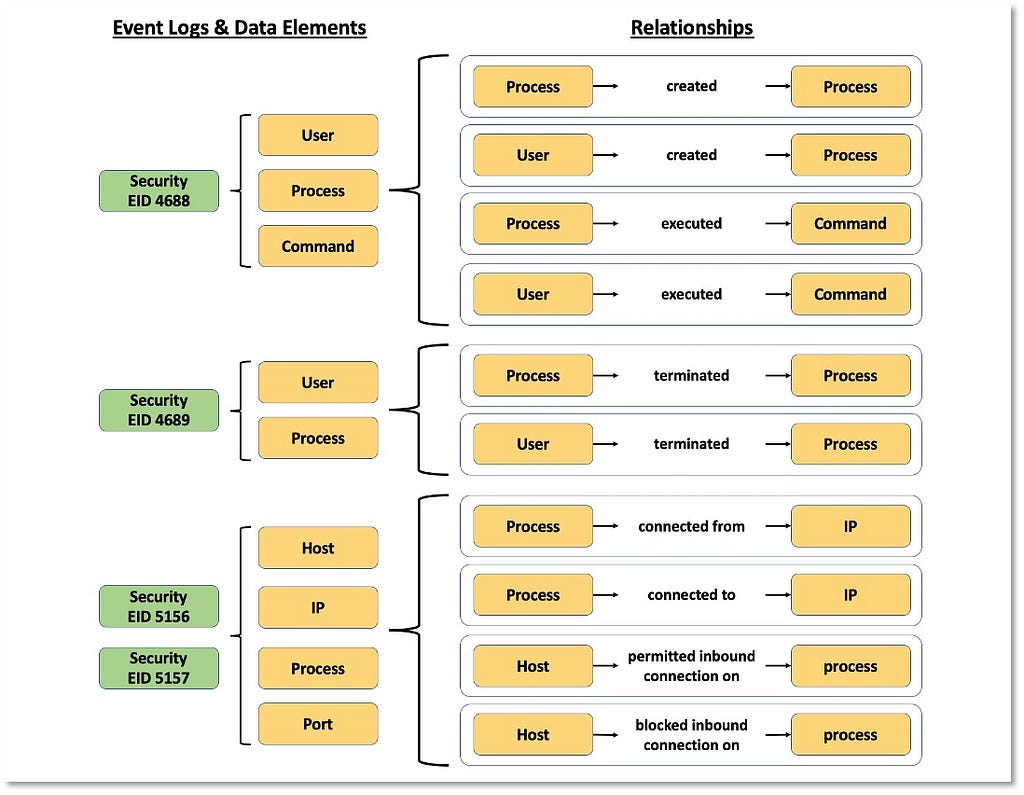
4) Defining Data Components: All of the combined information aspects in the previous steps contribute to the concept of data components in the framework.
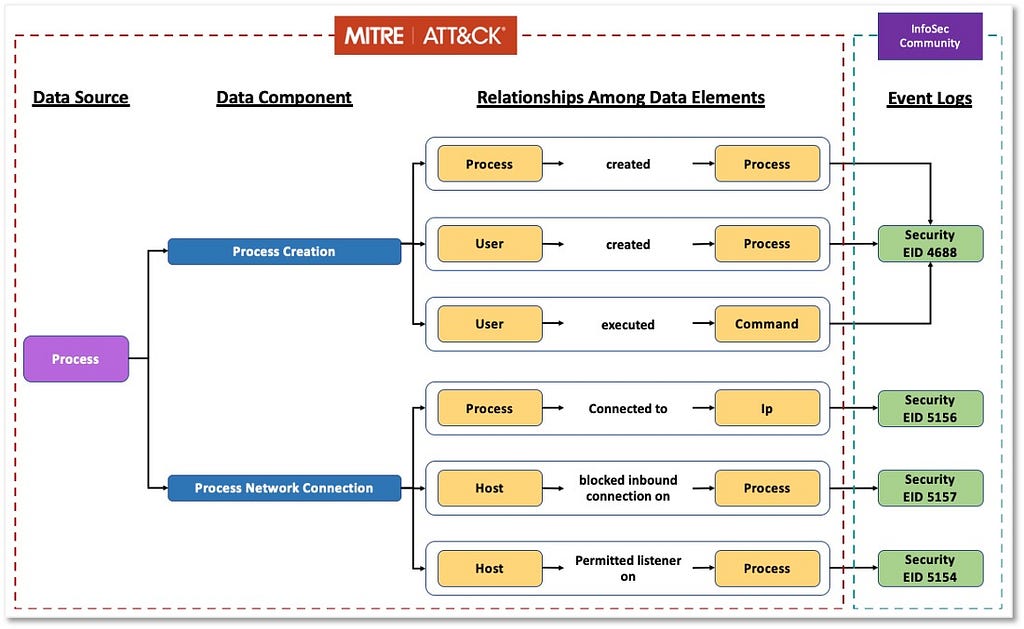
Based on the relationships identified among data elements, we can start grouping and developing corresponding designations to inform a high-level overview of the relationships. As highlighted in the image below, some data components can be mapped to one event (Process Creation -> Security 4688) while other components such as “Process Network Connection” involve more than one security event from the same provider.
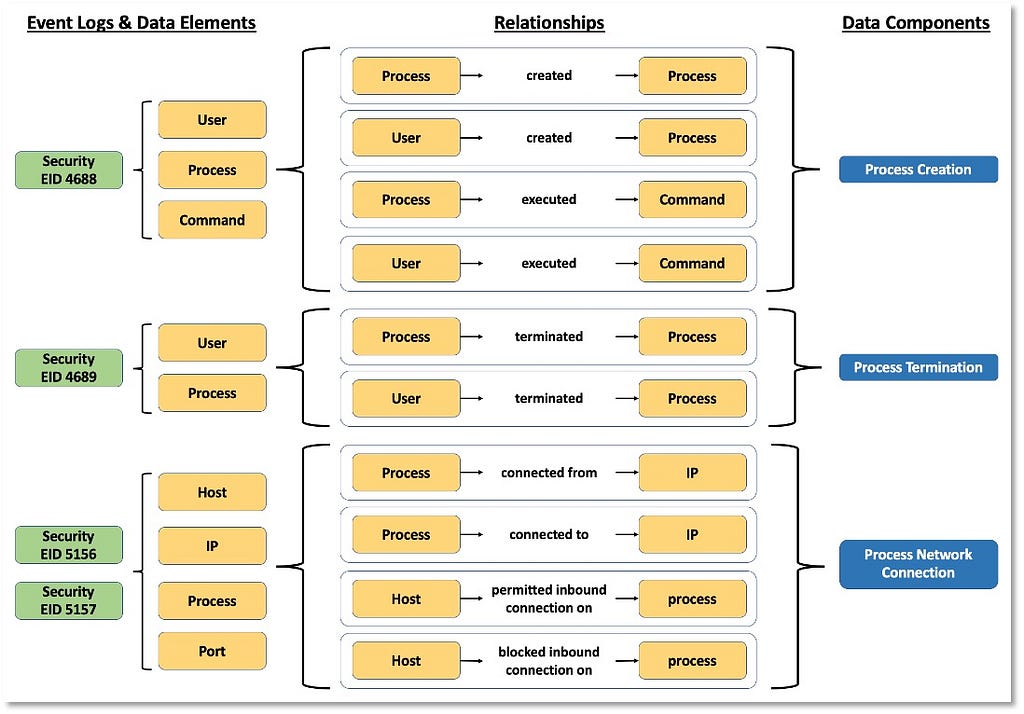
“Process” now serves as an umbrella over the linked information facets relevant to the ATT&CK data source.
5) Assembling the ATT&CK Data Source Object: Aggregating all of the core outputs from the previous steps and linking them together represents the new “Process” ATT&CK data source object. The table below provides a basic example of it for “Process”:
Improving Windows Event Logs
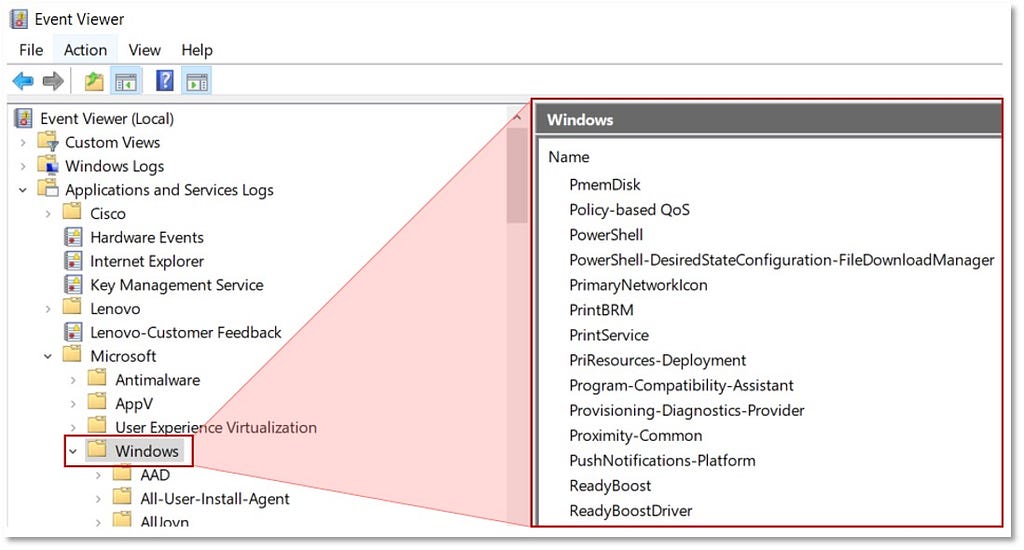
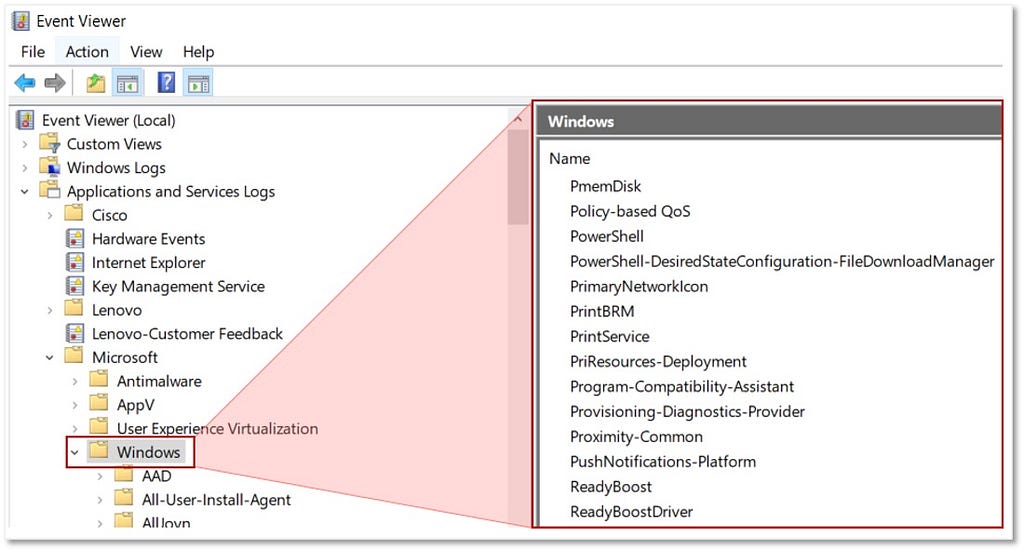
1) Identifying Sources of Data: Following the established methodology, our first step is to identify the security events we can collect pertaining to “Windows Event Logs”, but it’s immediately apparent that this data source is too broad. The image below displays a few of the Windows event providers that exist under the “Windows Event logs” umbrella.
The next image reveals additional Windows event logs that could also be considered sources of data.
With so many events, how do we define what needs to be collected from a Windows endpoint when an ATT&CK technique recommends “Windows Event Logs” as a data source?
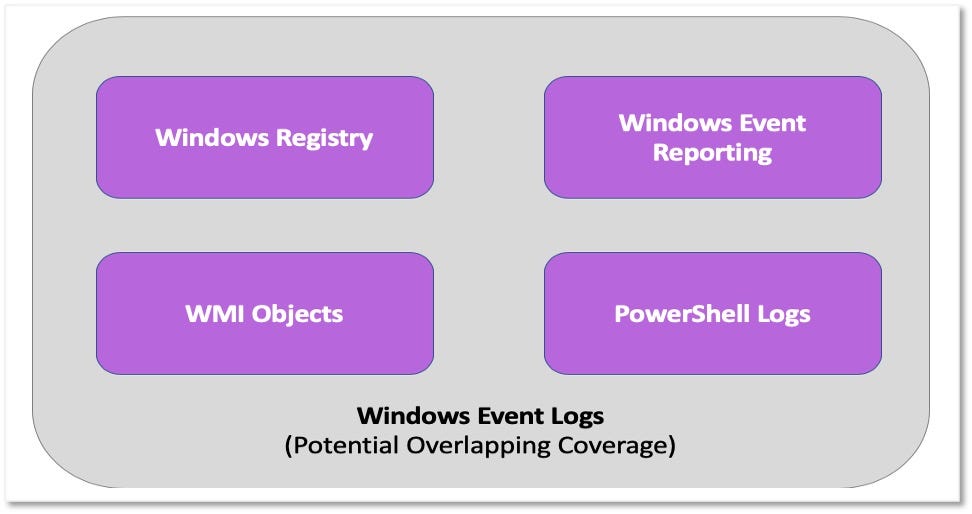
2–3–4) Identifying Data Elements, Relationships and Data Components: We suggest that the current ATT&CK data source Windows Event Logs can be broken down, compared with other data sources for potential overlaps, and replaced. To accomplish this, we can duplicate the process we previously used with Process Monitoring to demonstrate that Windows Event Logs covers several data elements, relationships, data components and even other existing ATT&CK data sources.
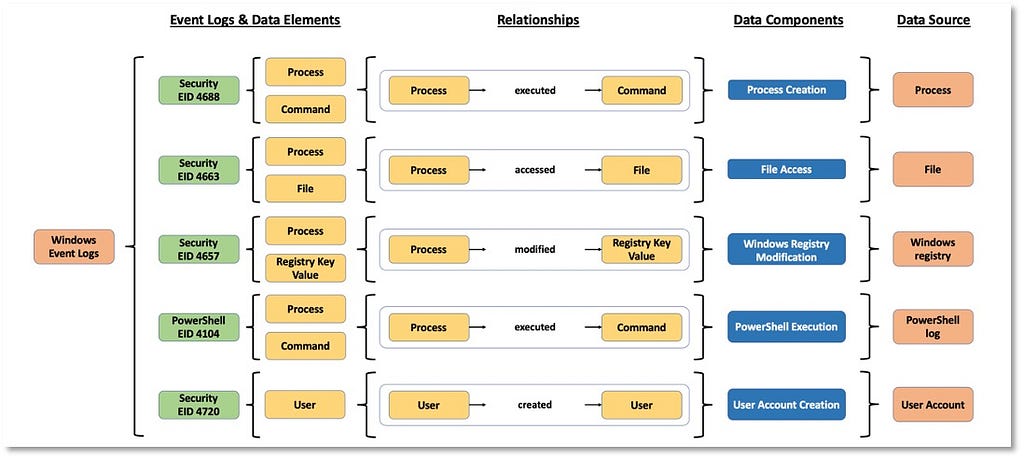
5) Assembling the ATT&CK Data Source Object: Assembling the outputs from the process, we can leverage the information from Windows security event logs to create and define a few data source objects.
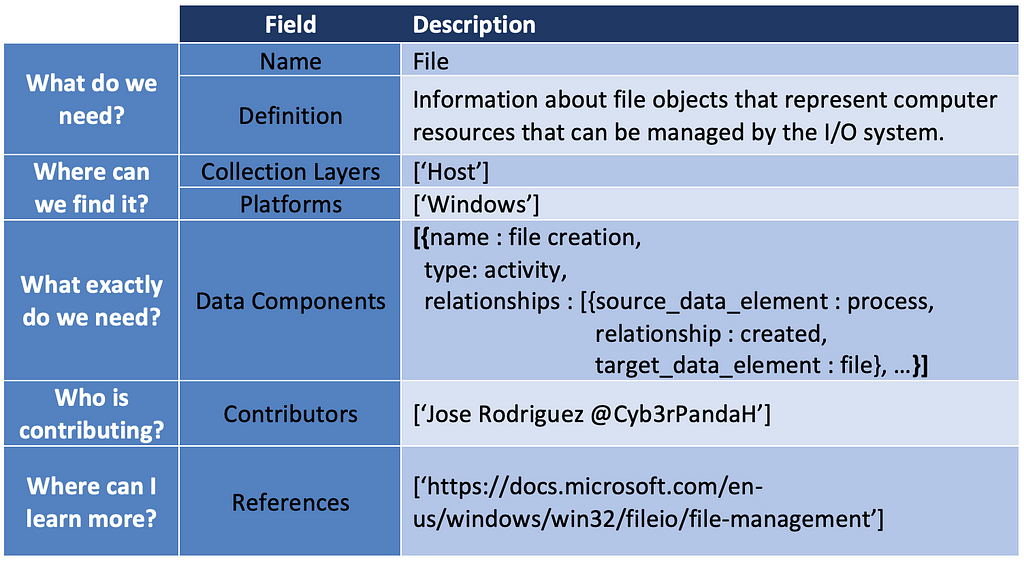
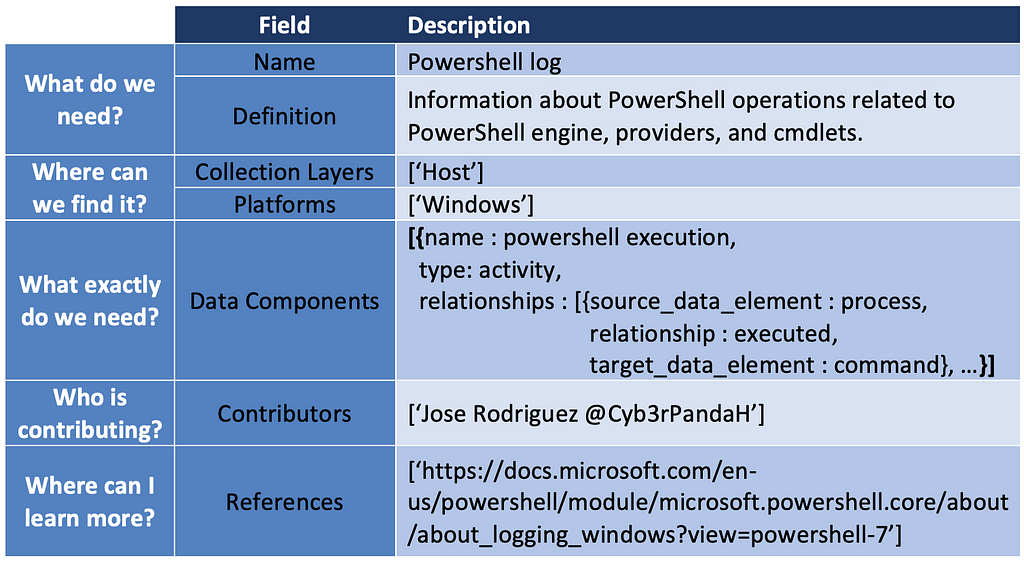
In addition, we can identify potential new ATT&CK data sources. The User Account case was the result of identifying several data elements and relationships around the telemetry generated when adversaries create a user, enable a user, modify properties of a user account, and even disable user accounts. The table below is an example of what the new ATT&CK data source object would look like.
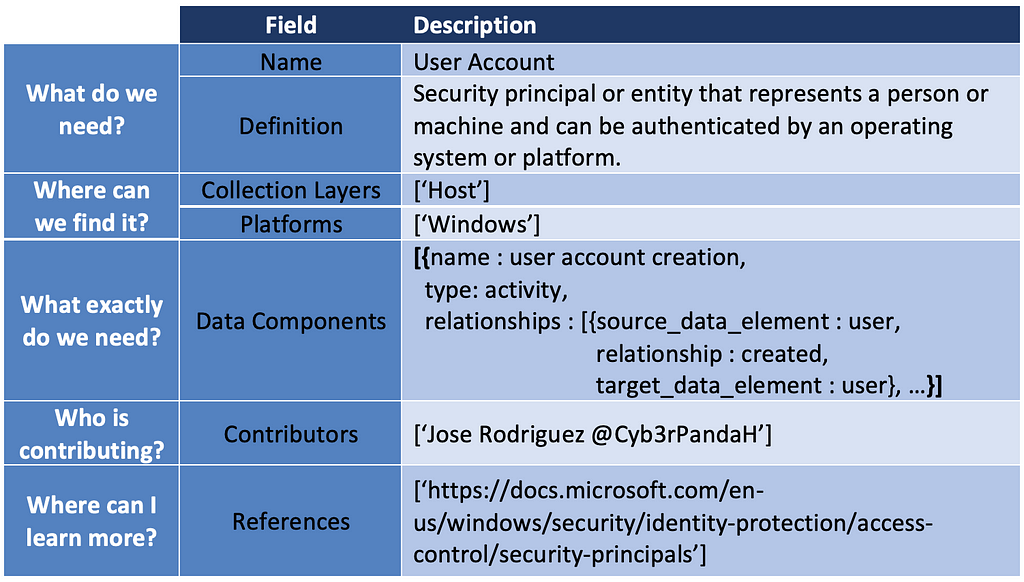
This new data source could be mapped to ATT&CK techniques such as Account Manipulation (T1098).
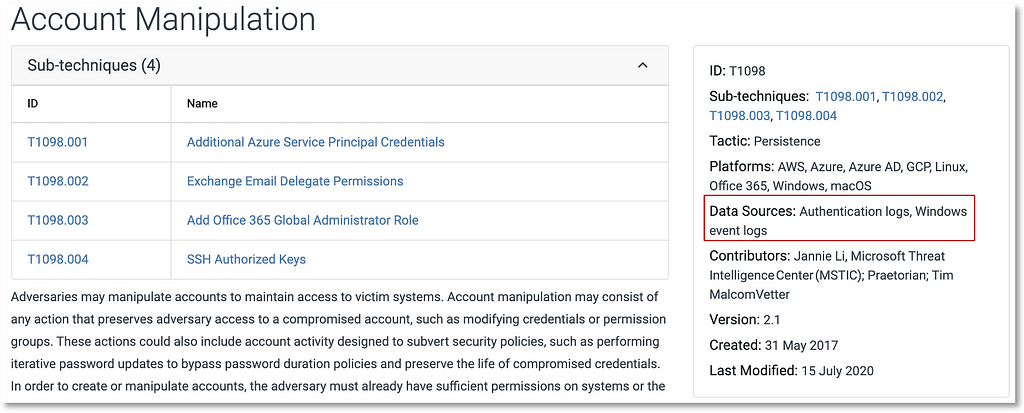
Applying the Methodology to (Sub-)Techniques
Now that we’ve operationalized the methodology to enrich ATT&CK data through defined data source objects, how does this apply to techniques and sub-techniques? With the additional context around each data source, we can leverage the results with more context and detail when defining a data collection strategy for techniques and sub-techniques.
Sub-Technique Use Case: T1543.003 Windows Service
T1543 Create and Modify System Process (used to accomplish Persistence and Privilege Escalationtactics) includes the following sub-techniques: Launch Agent, System Service, Windows Service, and Launch Daemon.
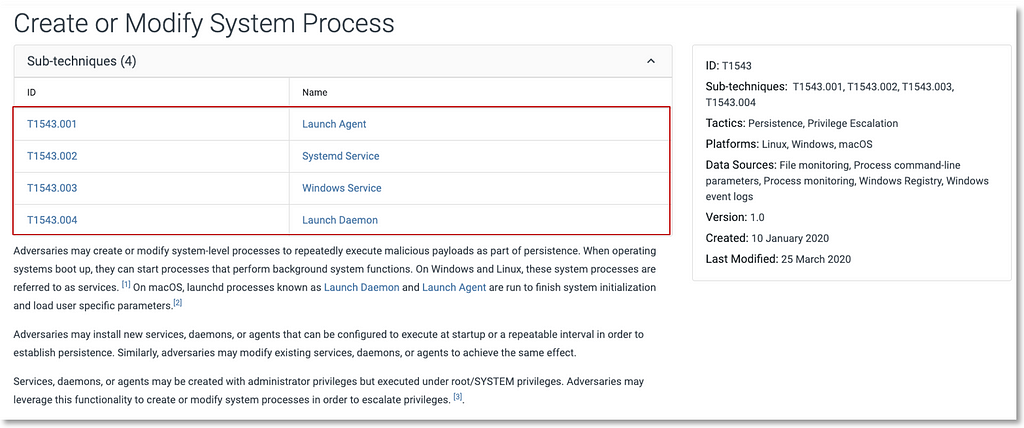
We’ll focus on T1543.003 Windows Service to highlight how the additional context provided by the data source objects make it easier to identify potential security events to be collected.
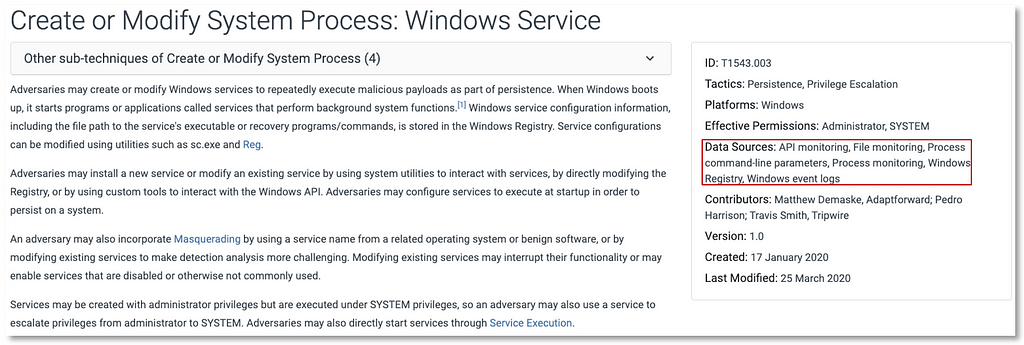
Based on the information provided by the sub-technique, we can start leveraging some of the ATT&CK data objects that can be defined with the methodology. With the additional information from Process, Windows Registry and Service data source objects, we can drill down and use properties such as data components for more specificity from a data perspective.
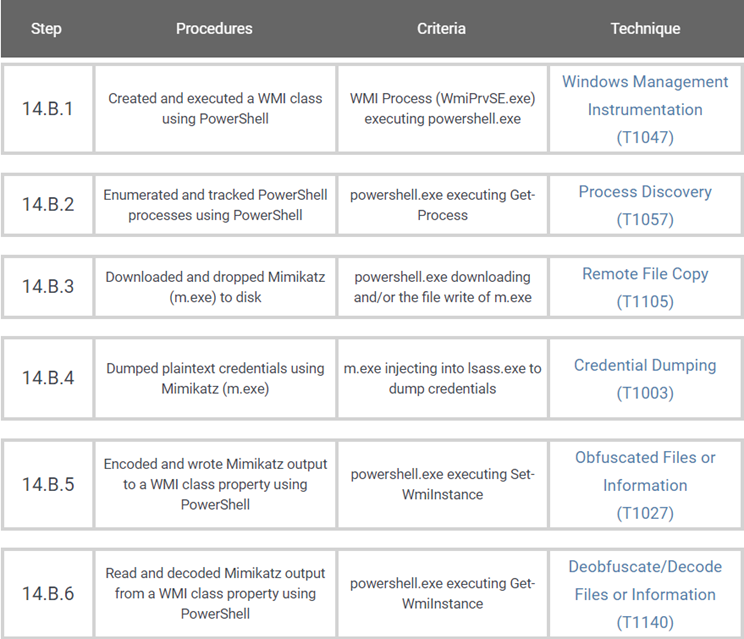
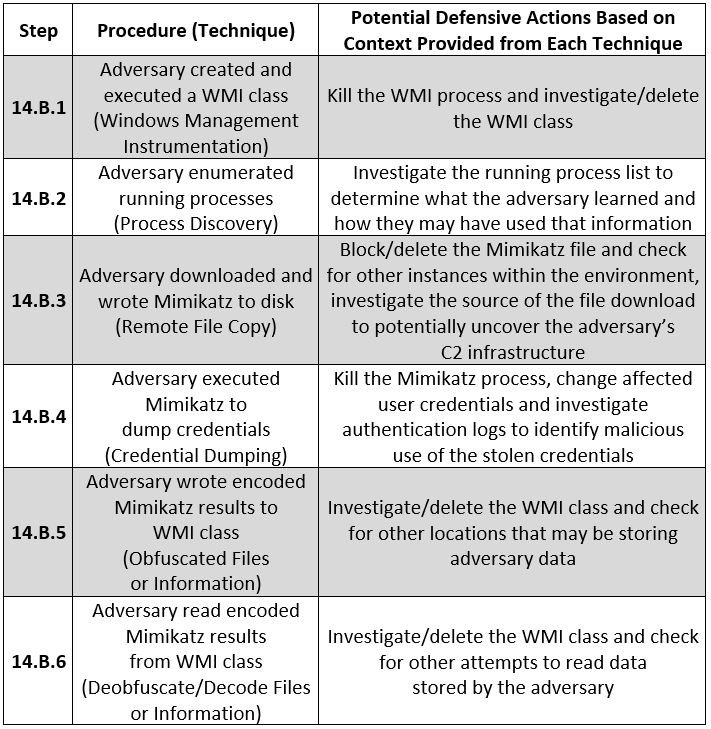
In the image below, concepts such as data components not only narrow the identification of security events, but also create a bridge between high- and low-level concepts to inform data collection strategies.
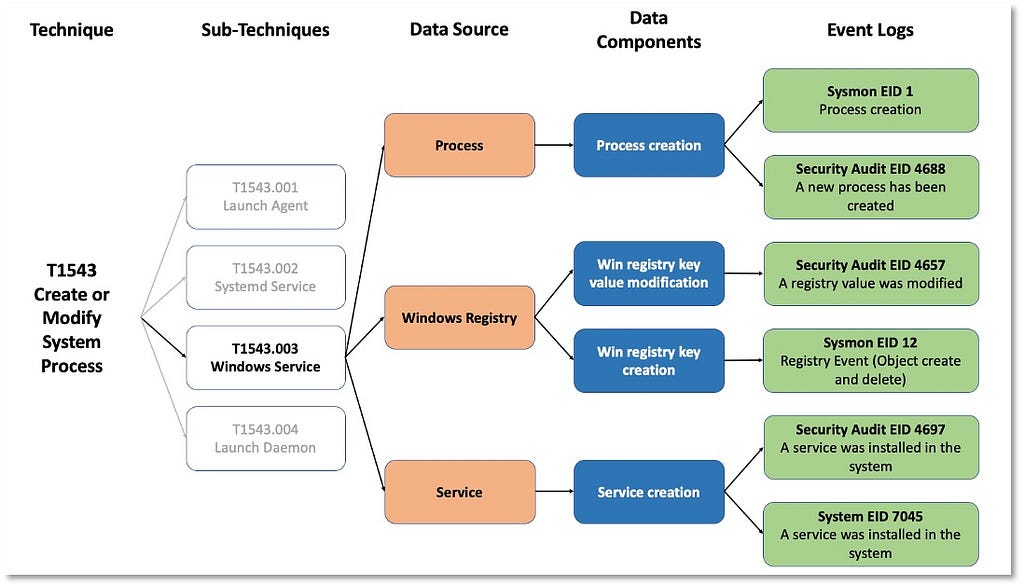
Implementing these concepts from an organizational perspective requires identifying what security events are mapped to specific data components. The image above leverages free telemetry examples to illustrate the concepts behind the methodology.
This T1543.003 use case demonstrates how the methodology aligns seamlessly with ATT&CK’s classification as a mid-level framework that breaks down high-level concepts and contextualizes lower-level concepts.
Where can we find initial Data Sources objects?
The initial data source objects that we developed can be found at https://github.com/mitre-attack/attack-datasources in Yaml format for easy consumption. Most of the data components and relationships were defined from a Windows Host perspective and there are many opportunities for contributions from collection layer (i.e. Network, Cloud) and platform (i.e. Mac, Linux) perspectives for applying this methodology.
Outlined below is an example of the Yaml file structure for the Service data source object:

Going Forward
In this two-part series, we introduced, formalized and operationalized the methodology to revamp ATT&CK data sources. We encourage you to test this methodology in your environment and provide feedback about what works and what needs improvement as we consider adopting it for MITRE ATT&CK.
As highlighted both in this post and in Part I, mapping data sources to data elements and identifying their relationships is still a work in progress and we look forward to continuing to develop this concept with community input.
©2020 The MITRE Corporation. ALL RIGHTS RESERVED. Approved for public release. Distribution unlimited 20–02605–3
Defining ATT&CK Data Sources, Part II: Operationalizing the Methodology was originally published in MITRE ATT&CK® on Medium, where people are continuing the conversation by highlighting and responding to this story.































 ‘
‘








































{kind=link}