Computer security, cybersecurity or information technology security is the protection of computer systems and networks from information disclosure, theft of or damage to their hardware, software, or electronic data, as well as from the disruption or misdirection of the services they provide.
November 1, 2022 Linux Fundamentals Lesson 7 : Managing Storage In Linux Exercises Introduction Lab Topology Exercise 1 — Managing Storage in Linux Review Learning Outcomes In this module, you will complete the following exercises: Exercise 1 — Managing Storage in Linux After completing this lab, you will be able to: Create a Partition in the Current Operating System Check the Status of the …
November 1, 2022 Linux FundamentalsLesson 8 : Application Installation In Linux Exercises Introduction Lab Topology Exercise 1 — Application Installation on Ubuntu Exercise 2 — Application Installation on Centos Review Learning Outcomes In this module, you will complete the following exercises: Exercise 1 — Application Installation on Ubuntu Exercise 2 — Application Installation on CentOS After completing this lab, you will be able to: Install & Remove Applications in CentOS …
November 1, 2022 Linux Fundamentals Lesson 9 : Service Management in Linux Exercises Introduction Lab Topology Exercise 1 — Service Management in Ubuntu Exercise 2 — Service Management in CentOS Review Start Learning Outcomes In this module, you will complete the following exercises: Exercise 1 — Service Management in Ubuntu Exercise 2 — Service Management in CentOS After completing this lab, you will be able to: Start and Stop Services …
November 1, 2022 Linux Fundamentals Lesson 10 : Managing Software Updates and Patches Exercises Introduction Lab Topology Exercise 1 — Updating an Ubuntu Operating System Exercise 2 — Updating a CentOS Operating System Review Learning Outcomes In this module, you will complete the following exercises: Exercise 1 — Updating an Ubuntu Operating System Exercise 2 — Updating a CentOS Operating System After completing this lab, …
By: Amy Robertson, Jared Ondricek, and Matt Malone
We’ve talked about building Campaigns into ATT&CK in our ATT&CK 2022 roadmap, at ATT&CKCon 3.0, and most recently on the SANS Threat Analysis Rundown but their release is now nigh! Our initial collection of Campaigns will be available starting with our ATT&CK v12 release on October 25, when you’ll be able to leverage the Campaigns structure for all of your ATT&CK use cases. Prior to the release, we’re taking the opportunity to walk you through our vision for Campaigns, give you a tour of Campaigns elements, and cover our longer-term Campaigns plans.
The Campaigns Vision
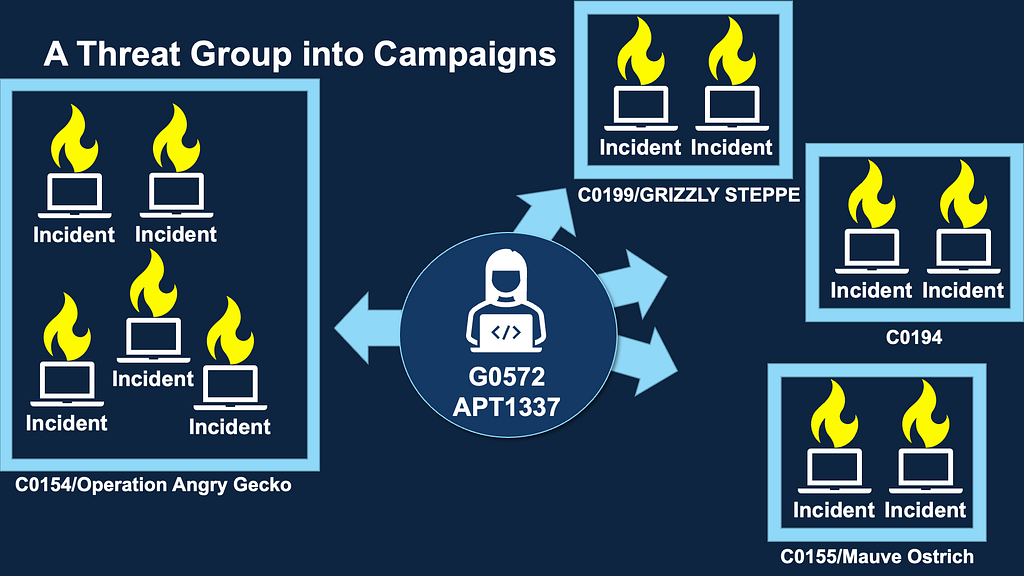
For our purposes in ATT&CK, we use “Campaigns” to describe a grouping of intrusion activity conducted over a specific period of time with common targets and objectives. A key aspect of Campaigns is that the activity may or may not be linked to a specific threat actor.
Our vision for Campaigns is to provide users with another way to view the evolution of malicious cyber operations. Threat actor activity in ATT&CK currently encompasses a broad set of behaviors that can inform a holistic picture of the adversary over time. But as adversaries evolve, their TTPs often change, and by introducing some structure with Campaigns, we hope to allow you to glean more actionable intelligence and context to inform your defense prioritization. Campaigns will enable you to identify trends, track significant changes in techniques used by various actors, and monitor the introduction of new capabilities (or exploited vulnerabilities). You’ll also be able to identify continued threat actor reliance on certain techniques regardless of the campaign objective and/or targets.
Campaigns will also allow us to more accurately categorize complex intrusion activity, including those involving multiple threats (such as Ransomware-as-a-Service operations) and parse out overlapping operations that have been given the same name. With the new structure, we’ll also be converting some of the Groups in ATT&CK to Campaigns. This will apply to Groups that meet our definition of a Campaign and only feature one cluster of activity (such as G0101/Frankenstein and G0014/Night Dragon).
As is our tradition of carefully integrating structural elements in ATT&CK, we’ll be incorporating a limited number of Campaigns into the v12 release. This initial collection of Campaigns will feature former Group entries that are more accurately categorized as Campaigns, a curated number of Campaigns linked to existing Groups, as well as unattributed Campaigns.
Campaign Elements
We structured Campaigns to visually align with Groups and Software pages, and the v12 release will feature an addition of a new “Campaigns” button on the main page tool bar for easy access.
Figure 1: Example of the new ATT&CK tool bar with the “Campaigns” button.
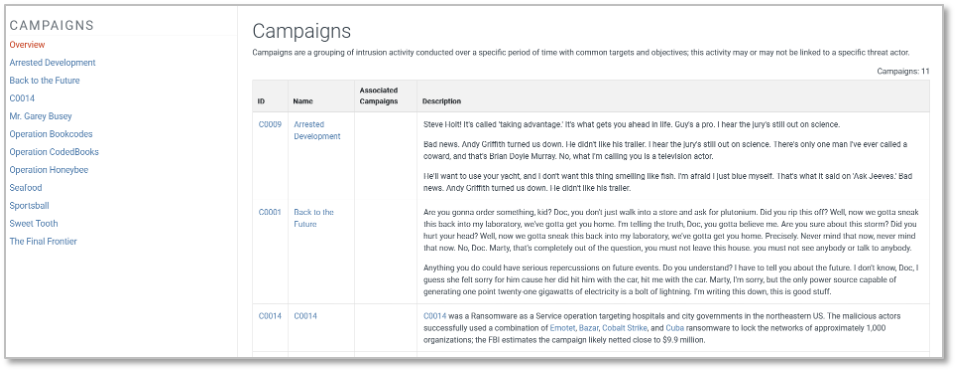
The Campaigns homepage will include a Campaigns table featuring ID number, Name, and activity descriptions. The list of available Campaigns in the left column highlights the Campaigns added or converted to date. As we previously covered, we created some flexibility in terms of whether or not the activity was given a unique name — a limitation we currently face with Groups — by allowing a Campaign to be simply referenced by our own identifier (e.g., C0014) if it doesn’t already come with a name.
Figure 2: A draft Campaign table, with unnamed activity referenced as C0014.
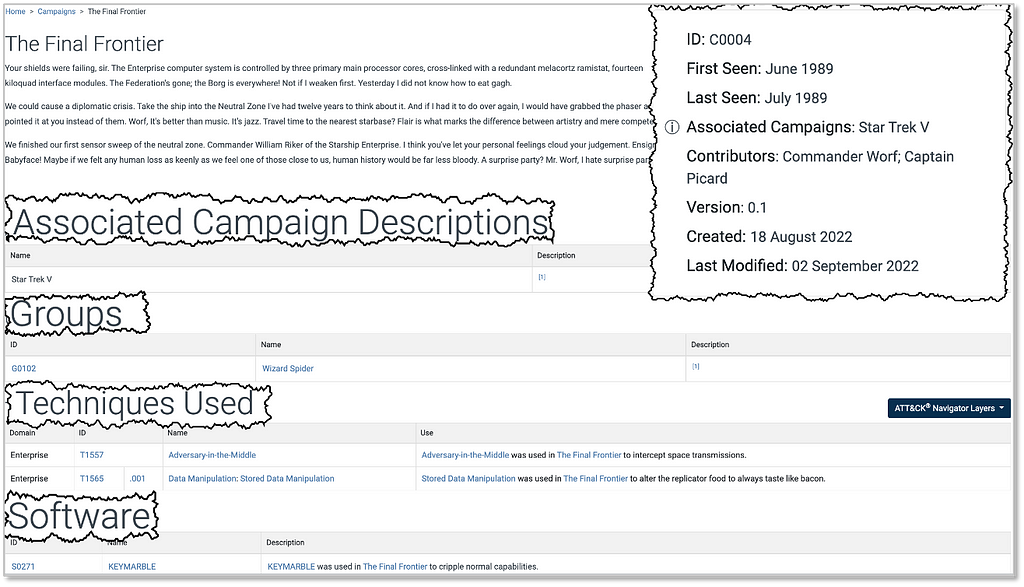
Each Campaign entry will feature a description of the intrusion activity, including details like known targeted countries and sectors where available, as well as any information that makes this Campaign particularly noteworthy.
Figure 3: A draft Campaign page for all of the Trekkies out there!
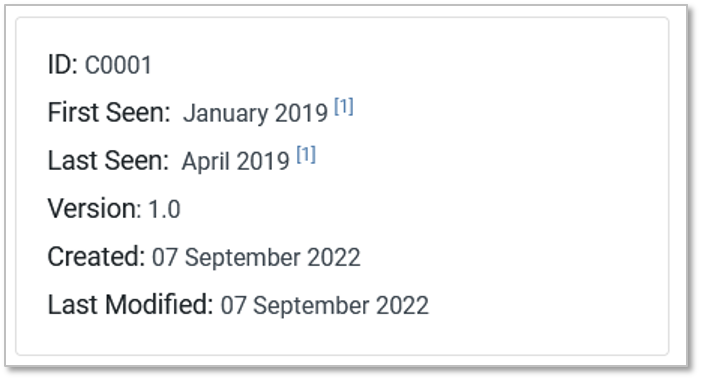
Something we’ve been particularly mindful of is how to best capture the period of time related to a Campaign. We opted for the “First Seen” and “Last Seen” fields in the information box, with the corresponding reference citations, so users can see how a Campaign was scoped. For intrusion activity assessed to be ongoing at the time of report publication, we’ll add language to that affect in the Campaign description (e.g., “As of September 2022 security researchers assessed this activity was ongoing”) and update future versions of ATT&CK Campaign entries accordingly.
Figure 4: An example Campaigns information box with time frame fields and citations.
As with Groups and Software, we’ve created a “Techniques Used” table to capture actor procedure examples observed during a Campaign, with a couple of significant differences.
1. We’ll add as much detail as reporting allows regarding specific commands or steps taken by the actors, to help ATT&CK users identify corresponding detection and mitigation opportunities. We’ve found this concept to be more challenging for Group and Software pages, as those tend to aggregate a variety of reporting examples over time, resulting in more generic procedure example language.
2. We’ll preface our Campaign procedure examples with the Campaign name or associated ID number, to separate it from techniques already found on a Group page. We realize the utility of this may not be immediately evident while looking at a Campaign page, but this allows for the procedure examples to stand out separately when a Campaign is associated with a Group (and, hopefully, allows for smoother integration in the future if an unattributed Campaign is later attributed to a Group).
Figure 5: Separate procedure examples as seen from a Group page, based on a fictional Campaign. The top line is the existing procedure example for T1566.001 for a Group, while the second line is specifically related to the associated Campaign.
What does this mean for Groups and Software?
We’ve made two key changes to Group and Software pages as they relate to Campaigns. As previously mentioned, techniques and corresponding procedure examples mapped to a Group-attributed Campaign will carry over to the associated Group page. We’ll also continue to map Campaign-specific procedure examples to Software pages.
We’ve added a Campaigns table to associated Group and Software pages, so ATT&CK users can easily reference Campaign ID numbers, Names (when applicable), and the Campaign description.
Group and Software pages will otherwise remain visually unchanged, and we’ll continue to update them separately as a collective list of all observed techniques. We want to preserve the functionality of ATT&CK Navigator Layers in that respect, for ATT&CK users who want to focus on all techniques used regardless of time or target.
Introducing the Campaign STIX Object
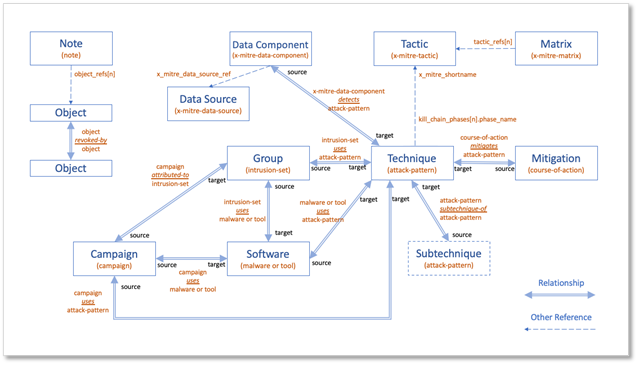
With the addition of Campaigns to ATT&CK, the ATT&CK Data Model (which can be found in our Usage document), has expanded to encompass these changes. The diagram below portrays how all the moving pieces work together, with the new additions of the Campaign object type and the Relationships connected to Campaigns. It’s important to note, there are no changes to objects that previously existed in ATT&CK. Software written to read earlier versions of ATT&CK should continue to work, albeit missing data that only appears in Campaigns.
Figure 6: Campaign STIX relationships
Now that you’ve seen our data model, we’d like to introduce you to the star of the show — the STIX Campaign object. As a part of the ATT&CK Data Model, it makes use of the same STIX extensions that can be found there, such as x_mitre_version. However, in addition to those previously documented fields, here is the breakdown of how ATT&CK utilizes each field that is unique to the Campaign object:
Standard STIX fields:
type: Follows the STIX specification
name: The name used to identify the Campaign. If no name is given, then this field will contain an ATT&CK identifier in the form CXXXX
description: Follows the STIX specification
aliases: Used to hold associated Campaign names
first_seen (timestamp): The time frame that this Campaign was first seen. ATT&CK makes use of this field only to the level of granularity of month/year. The day and time part of this timestamp field should be ignored by parsers when displaying ATT&CK Campaign information
last_seen (timestamp): The time that this Campaign was last seen or reported. ATT&CK makes use of this field only to the level of granularity of month/year. The day and time part of this timestamp field should be ignored by parsers when displaying ATT&CK Campaign information
objective: Not used by ATT&CK
Extensions of the STIX Spec:
x_mitre_first_seen_citation (string): One to many citations for when the Campaign was first reported in the form “(Citation: <citation name>)” where <citation name> can be found as one of the source_name of one of the external_references.
x_mitre_last_seen_citation (string): One to many citations for when the Campaign was last reported in the form “(Citation: <citation name>)” where <citation name> can be found as one of the source_name of one of the external_references.
As mentioned above, we have also added three new STIX Relationships that connect Campaigns to the rest of the ecosystem; namely that Campaigns can optionally be attributed to a Group, use Software, or use Techniques. The STIX Relationship objects themselves have no special modifications from the STIX standard and simply connect Campaigns to those previously existing objects. At a glance this seems straightforward enough, but there are some things to be aware of if you are parsing ATT&CK v12 STIX going forward.
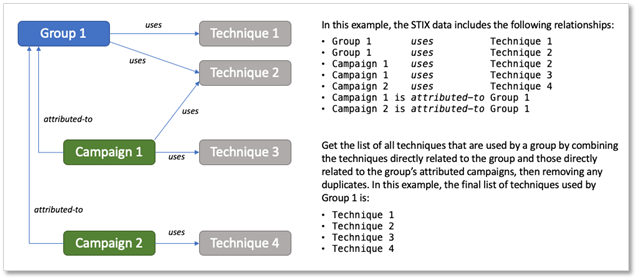
When gathering data about Groups that have Campaigns attributed to them, it’s a bit more complex to parse out all the Techniques and Software that are used by the Group. For Campaigns associated with a Group, we won’t be creating relationships between techniques and Software in that Campaign and the Group, if you would like to view the inclusive list, you’ll need to combine technique sets and Software usage.
Combining Technique Sets: To get a comprehensive Group Technique view, you’ll need to combine the set of Techniques that are directly used by the Group with the set of Techniques used by all of their associated Campaigns.
Figure 7: Example of Group Technique STIX inheritance
Mapping Software Object Usage: To holistically map out Software object usage, you’ll identify the Groups, the Group-attributed Campaigns, and the unattributed Campaigns using the Software, and combine them for the full picture.
For further technical details on how to handle retrieving all Techniques or Software that a Group uses starting with the v12 release and how it differs from the v11 and prior releases, please refer to the Relationships Microlibrary section of the GitHub Usage document.
What to Expect Going Forward
We’ll continue modifying and building out Campaigns, with the eventual goal of revisiting a major Group pages in ATT&CK and reconstructing earlier Campaigns to reflect how these actors have evolved over time. We’ll also shift focus from one-off or unattributed Campaigns to more complex Campaigns attributed to some of the more populated Group entries, such as the SolarWinds intrusion and G0016/APT29.
Campaigns will also serve a key role in tying together the various ATT&CK matrices — Enterprise (Cloud, Containers, macOS, and Linux), Mobile, and ICS, to further document how adversaries pivot across these domains using a variety of techniques to accomplish their objectives.
We greatly appreciate the community’s feedback on Campaigns to date, and as we continue to develop Campaigns, we welcome your input. Our Contributions page will be updated in the near future to include more detailed guidance and we look forward to connecting with you via email, Slack, or Twitter.
Introducing ATT&CK Campaigns was originally published in MITRE ATT&CK® on Medium, where people are continuing the conversation by highlighting and responding to this story.
Right on cue, ATT&CK’s latest release is out, and this time we’ve gone to v11! If you’ve been following along with our roadmap there shouldn’t be any huge surprises in store, but we wanted to take a chance to go over our latest changes. The v11 set list includes detections now paired with related Data Sources: Data Components, a beta version of sub-techniques for ATT&CK for Mobile, ATT&CK for ICS on attack.mitre.org, as well as regular updates/additions across Techniques, Software, and Groups.
ATT&CK for Enterprise Structured Detections
Over the past few years, transforming various actionable ATT&CK fields into managed objects has been a reoccurring theme. In v5 of ATT&CK, we converted mitigations into objects to enhance their value and usability — with this conversion, you can now identify a mitigation and pivot to various techniques it can potentially prevent. This has been a feature that many of you have leveraged to map ATT&CK to different control/risk frameworks. We previously converted data sources to objects for the v10 release, enabling similar pivoting and analysis opportunities.
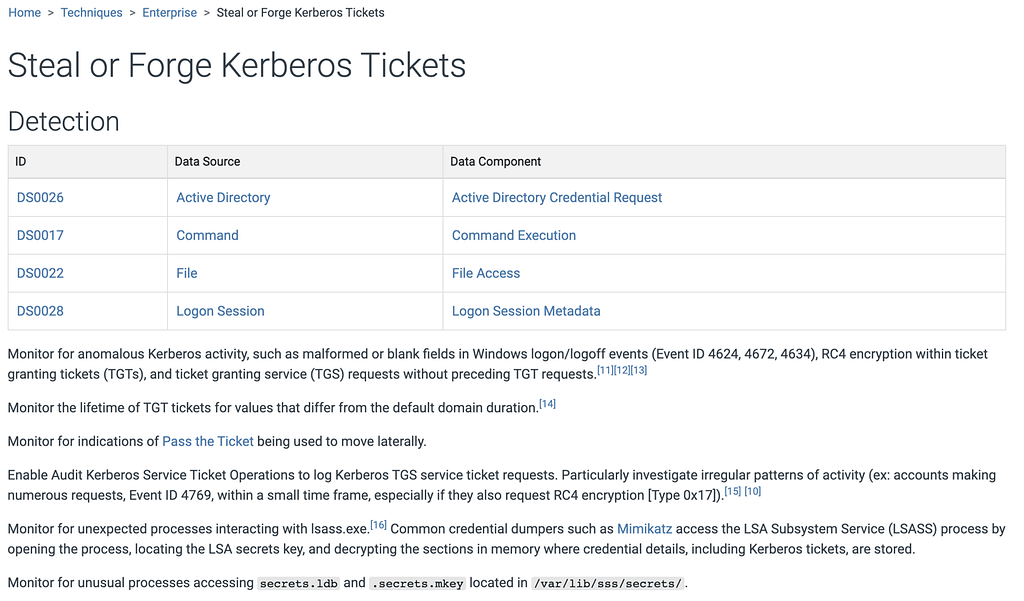
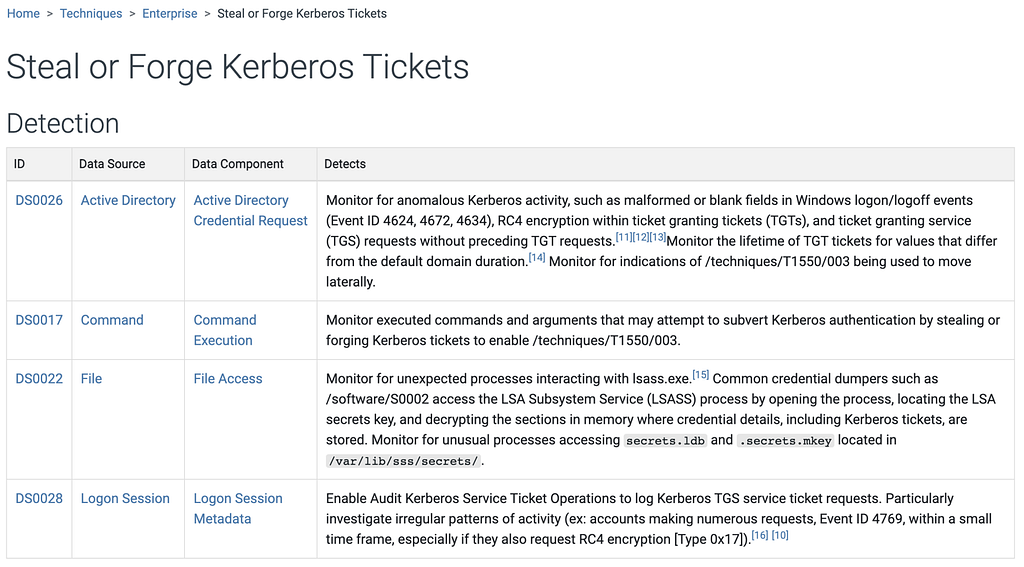
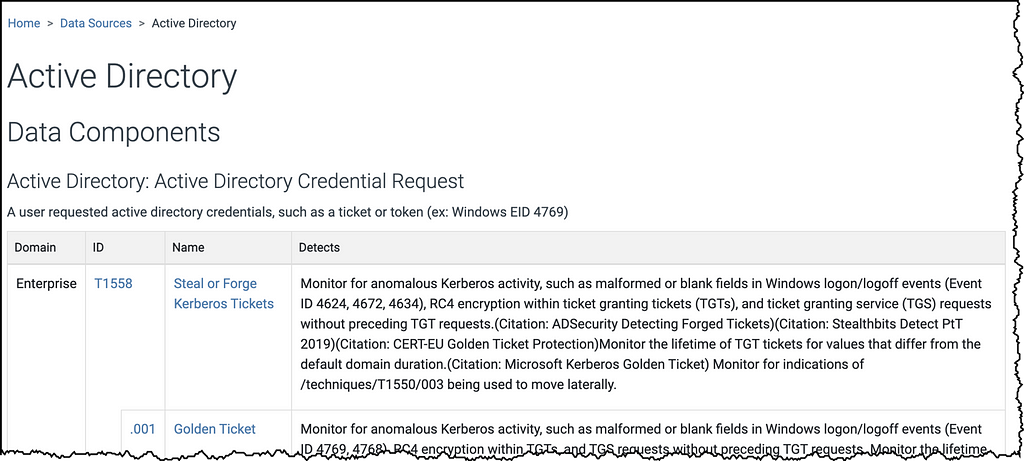
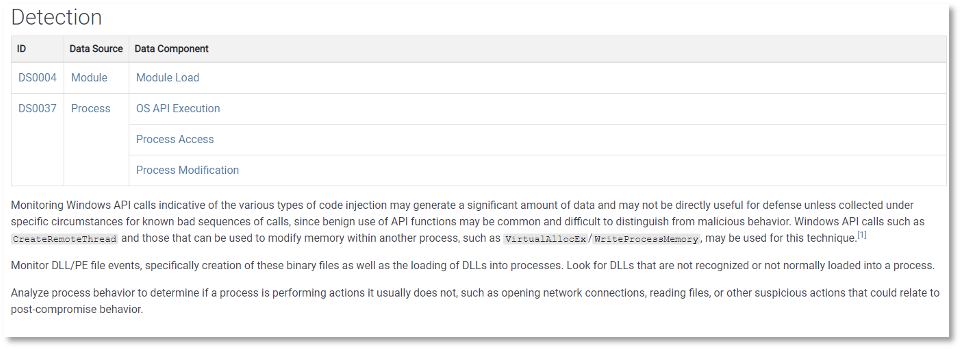
In today’s v11 release we’ve taken a parallel approach for detections in Enterprise ATT&CK, taking the previously free text detections featured in Techniques, and have refined and merged them into descriptions that are connected to Data Sources. We have typically tried to match the detection text on a Technique to its Data Sources, but this makes the paring explicit. This will let you now see for each detection what you need to collect as inputs (Data Sources) paired with how you could analyze that data to identify a given Technique (detection). Below is an example of how Data Sources and Detections have changed for Steal or Forge Kerberos Tickets (T1558).
Data sources and detections in ATT&CK v10 for Steal or Forge Kerberos Tickets (T1558)Data sources and detections in ATT&CK v11 for Steal or Forge Kerberos Tickets (T1558)
Detections will also now be included on Data Source pages, associated with each Technique listed for a Data Component.
As with everything else in ATT&CK, these new detections also appear in our STIX as a part of the “detects” relationship added in our last ATT&CK release in its “description” field. For more information about ATT&CK’s STIX representation, including the data source objects and relationships added in ATT&CK v10, you can check out our STIX usage document.
Mobile Sub-Techniques Beta
In 2020, we added Sub-Techniques to ATT&CK for Enterprise. In the time since, they’ve been well-received and solved some of the growth issues we were having in our biggest matrix. As ATT&CK’s Mobile Lead Jason Ajmo recently talked about in the ATT&CK Blog, we’re now bringing this improvement to ATT&CK for Mobile as a beta release. The content on the main ATT&CK site now contains the Sub-Techniques beta, and the current, stable Mobile content can be accessed at https://attack.mitre.org/versions/v10/matrices/mobile/. We plan on making ATT&CK for Mobile with Sub-Techniques final this summer, after we’ve given the community time to check out the content, get ready for it, and send us any feedback they have to [email protected]. Until that time, the main STIX representation of ATT&CK for Mobile will remain the v10 pre-Sub-Techniques version.
How can I move to the beta ATT&CK for Mobile with sub-techniques?
First, you’ll need to support some changes to Mobile ATT&CK’s technique structure necessary to support sub-techniques. If you’re already using or have moved to versions of ATT&CK for Enterprise with sub-techniques, the structural changes and the process of moving are identical. As with ATT&CK for Enterprise, we’ve expanded Mobile technique IDs to identify corresponding sub-techniques: T[technique].[sub-technique]. In Mobile’s STIX representation of ATT&CK we’ve added the “x_mitre_is_subtechnique = true” to “attack-pattern” objects that represent a sub-technique, and “subtechnique-of” relationships between techniques and sub-techniques. Both are already contained in our STIX documentation. You can find a STIX representation of ATT&CK that includes the v11 Mobile Beta here.
Next, if you want to get a head start and remap your content from a previous version of Mobile ATT&CK, to this beta release. As we did when we released Sub-Techniques for ATT&CK for Enterprise, we’re providing a translation table or “crosswalk” from previous release Mobile technique IDs to beta ones to help with the transition. The JSON file shows what happened to each technique in the beta release. The top-level technique ID represents each technique from the v10 release, and the structure underneath shows what changed with the v11 beta release, if anything.
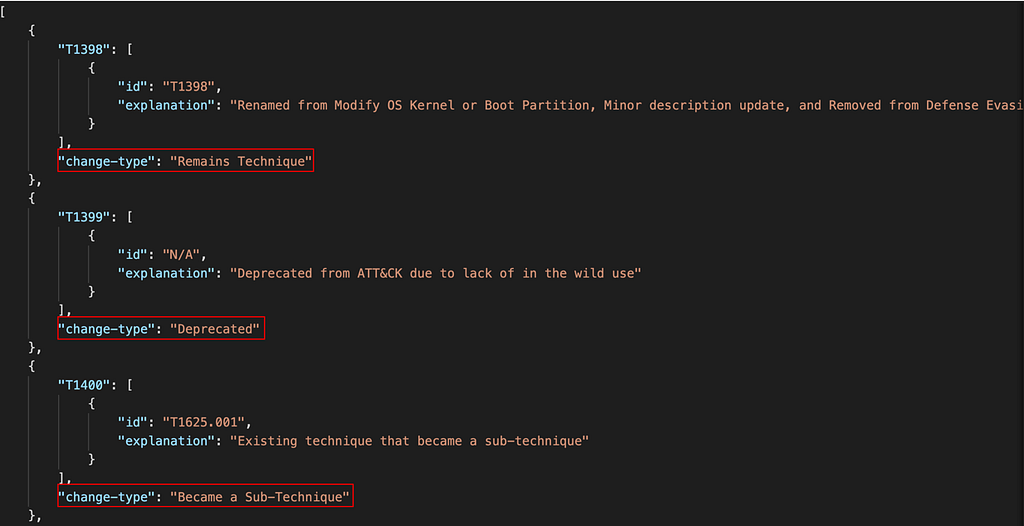
Thanks to the excellent feedback from the community, we identified four key types of changes:
Remains Technique
Became a Sub-Technique
One or More Techniques Became New Technique
Deprecated
Each of these types of changes is represented in the “change-type” field in the JSON. Some of these changes are simpler to implement than others. We recognize this, and in the following steps, we incorporate the four types of changes into tips on how to move from our previous release to ATT&CK with sub-techniques.
Step 1: Start with the easy to remap techniques first and automate
For “Remains Technique”, “Became a Sub-Technique”, or “One or More Techniques Became New Technique” change types you can replace the previous technique ID with the new technique ID.
In some cases, technique names have changed, or tactics have been removed, so it’s also worth checking the “explanation” in the JSON.
Remains Technique
The first thing that’s easy to remap — the techniques that aren’t changing and don’t need to be remapped. Anything labeled “Remains Technique” is still a technique with an unchanged technique ID like T1398 in the above example.
Became a Sub-Technique
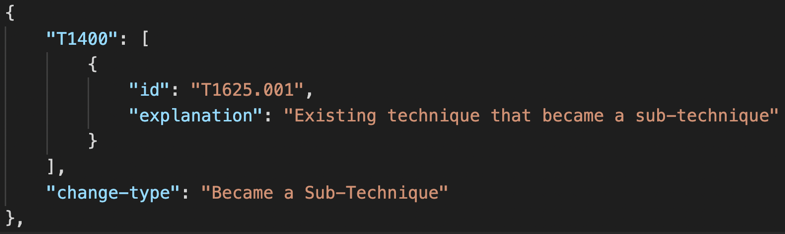
Next in the “easy to remap category” are the technique to sub-technique transitions, labeled “Became a Sub-Technique”. These techniques were converted into the sub-technique of another technique. In this example, Modify System Partition (T1400) became Hijack Execution Flow: System Runtime API Hijacking (T1625.001).
Finally, there are a few techniques that merged with other techniques.
One or More Techniques Became New Technique
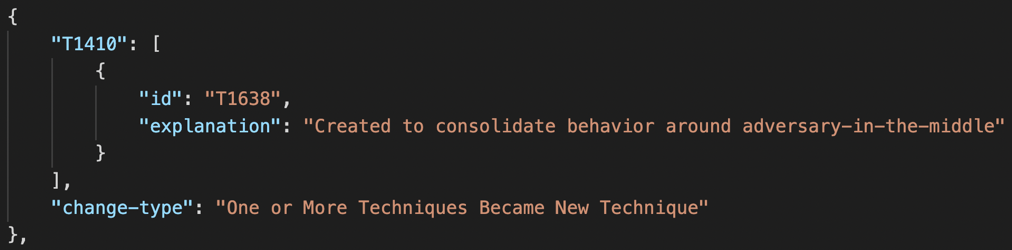
For techniques labeled “One or More Techniques Became New Technique” a new technique was created covering the scope and content of one or more previous techniques. For example, Network Traffic Capture or Redirection (T1410) and a few other techniques merged together to create Adversary-in-the-Middle (T1638).
For any of these “easy” types of changes anything represented by the previous ATT&CK technique ID should be transitioned to the new technique or sub-technique ID. The ATT&CK STIX objects represent this type of change as a revoked object which leaves behind a pointer to what they were revoked by. In the case of T1400, that means it was revoked by T1625.001.
In all of these cases, it’s enough to take what’s listed as the top-level key and replace it with what’s listed in the nested “id” key.
Step 2: Look at the deprecated techniques to see what changed
This is where some manual effort will take place. Deprecated techniques are not as straightforward.
Deprecated
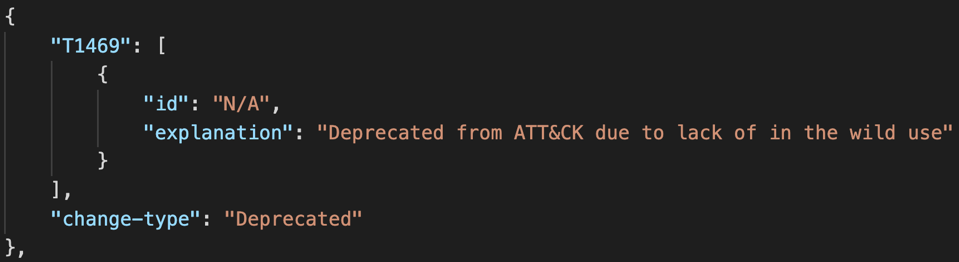
For techniques labeled as “Deprecated”, we removed them from ATT&CK without replacing them. They were deprecated because we felt they did not fit into ATT&CK or due to a lack of observed in the wild use. For example, Remotely Wipe Data Without Authorization (T1469) was removed because we hadn’t been able to find evidence of any adversary using it in the wild.
Step 3: Review the techniques that have new sub-techniques to see if the new granularity changes how you’d map
If you want to take full advantage of sub-techniques, there’s one more step. Many “Remains Technique” techniques now have new sub-techniques you can take advantage of.
One great example of an existing technique that now has new sub-techniques is Application Discovery (T1418). Its name was updated to Software Discovery, and its content was broken out into a new sub-technique: Security Software Discovery (T1418.001).
The new sub-techniques add more detail and taking advantage of them will require some manual analysis. The good news is that the additional granularity will allow you to represent different types of software discovery that can happen at a more detailed level. These types of remaps can be done over time, because if you keep something mapped to Software Discovery, then it’s still correct. You can map new stuff to the sub-techniques and come back to the old ones to make them more precise as you have time and resources.
TL;DR, if you do just Step 1 while mapping things that are deprecated to NULL, then it will still be correct. If you do Step 2, then you’ll have pretty much everything you mapped before now also mapped to the new Mobile ATT&CK. If you complete Step 3, then you’ll get the newfound power of sub-techniques!
What’s changed? First off, ATT&CK for ICS will no longer have that nostalgic ATT&CK Wiki look and feel, and links to ATT&CK for ICS will need to be updated. Second, we’ve merged the Groups and Software from ICS, adding ICS techniques to Group and Software pages that existed on both sites, and updating descriptions to include both.
Finally, we’ve merged Data Sources and Data Components in from ATT&CK for ICS. Since there’s quite a bit of overlap between ICS and Enterprise Data Sources we’ve added a filter that allows you to see just Enterprise, just ICS, and all Data Sources and Components on both the overall Data Sources list and individual Data Source pages.
What hasn’t changed? ATT&CK for ICS’s content hasn’t changed and its STIX representation remains in the same place. We will also be keeping the previous website in place until October 2022 to avoid breaking your deep links. We will have increasingly dire warnings on each page reminding people to update their links before it is eventually deprecated. In the future, content will only be updated on attack.mitre.org and not the MediaWiki site.
What’s Left in 2022?
We’ve just released our 2022 roadmap and continue to work across the framework. In v12 we plan on adding a new object related to groups in ATT&CK, Campaigns. Check out the slides from Matt Malone’s talk from ATT&CKcon 3.0, our recent roadmap blog post, or stay tuned for more details coming soon about their implementation.
We continue our work on improving the macOS platform and plan to focus on improvements to Linux between now and October. Please reach out to us via [email protected] or via our Slack if you’d like to contribute knowledge of what adversaries have been up to on either platform.
As always, if you have feedback, comments, contributions, or just want to ask questions, connect with us on email, Twitter, or Slack.
ATT&CK Goes to v11 was originally published in MITRE ATT&CK® on Medium, where people are continuing the conversation by highlighting and responding to this story.
Guest Post by ATT&CKcon 3.0 Keynote Speaker, Selena Larson
Allan Pinkerton (Alexander Gardner — Library of Congress)
At the onset of the Civil War, a man whose name would eventually become synonymous with famous American detectives was reportedly providing false reports to the Union’s top general. Allan Pinkerton, who once successfully smuggled Abraham Lincoln into Washington, D.C. to avoid a rumored assassination attempt before he was even sworn in as president, acted as General George McClellan’s top intelligence officer. He was considered one of the best spymasters in the United States, responsible for effectively founding the nation’s first secret service.
In this piece, we’ll dive into some major intelligence reporting failures that dogged the renowned spymaster, how effective and concise intelligence reporting can change the course of history, and how the MITRE ATT&CK framework can help streamline and effectively communicate actionable threat intelligence.
Pinkerton was a detective when he first got to know Lincoln, but quickly became an indispensable intelligencer for the Union, first in the nation’s capital and then on the battlefield, working as a Civil War spymaster in 1861–1862. He operated a large team of spies who conducted counterespionage operations throughout Washington and information gathering expeditions into enemy territory. Pinkerton’s successes and failures are many — he made many of his own tactical intelligence failures that cost at least one spy his life during the Civil War — but there is a lot modern day intelligence analysts can learn from him. Specifically, from his intelligence reports.
According to author Douglas Waller, author of Lincoln’s Spies, Pinkerton was not very good at validating or communicating information, or transforming it from data into intelligence. Throughout his time operating a secret service on behalf of the Union, he collected a lot of information. But that information was frequently poorly vetted, based on single sources, or received from biased narrators. And often, the information was ineffectively communicated, or outright falsified.
By dissecting the failures of the nation’s first intelligence service spymaster, modern day threat intelligence analysts can learn how and why effective intelligence communication and report writing can have major effects on an organization — and, in some cases, have the potential to change the course of history.
HiPPO Bias
One of the biggest failures plaguing Pinkerton’s reporting apparatus was his desire to please his boss. General McClellan was famously slow to take any offensive actions against the enemy, holding a deep fear of failure that paralyzed him into inaction.
McClellan reportedly believed the Confederate military to be much larger than it actually was, in part due to the “intelligence” provided to him by his top spy. In fact, the relationship between Pinkerton and McClellan was more like a self-licking ice cream cone. While stationed with McClellan in Washington, Virginia, and Maryland, Pinkerton worked his network of operators to collect information on enemy troop movement and the size of the Confederate army. Sometimes information proved to be correct; other times it was outright false. But in most cases, Pinkerton cherry-picked data that supported his boss’s beliefs of an opposing force either equal to or out-sizing the Union military, ignoring accurate information on the small size of the Confederate forces and further inflating already inflated estimates to appeal to McClellan’s beliefs.
“Loyal to the point of sycophancy, Pinkerton never doubted the general’s ability as a commander. Instead of serving his country or his president as a true intelligence officer, he made his friend happy.” Lincoln’s Spies
Pinkerton was demonstrating Highest Paid Person’s Opinion (HiPPO) bias, or the idea that analysts collect and disseminate information in a way that favors or appeals to existing beliefs within an organization, typically driven by leadership.
“Pinkerton admitted that he and McClellan had conspired to cook the books. In a later November 15 letter to the general, Pinkerton explained that his estimate of Confederate strength ‘was made large, as intimated to you at the time, so as to be sure to cover the entire number of the Enemy that our army was to meet.’ The controversial sentence appeared to show that before Pinkerton issued his October 4 report [reporting double the total number of actual Confederate troops], he and McClellan agreed to deliberately inflate the confederate numbers to be sure they included troops Pinkerton’s agents might not know about. ”
This can be a frequent issue for analysts tasked with certain objectives and directives, but it can also be detrimental to the organization’s decision making and ultimate success. For example, if leadership believes that Russian state-sponsored threats are the most important and likely the most targeted to their organization, defenders and analysts will be spending more key resources hunting for and defending against these threats, with the potential to miss or disregard tactics, techniques, and procedures (TTPs) associated with other relevant, but different, activity.
Use data to build your case. In her 2019 ATT&CKcon 2.0 keynote, Google’s Toni Gidwandi explained how the MITRE ATT&CK matrix can be a “powerful corrective” to HiPPO bias and enable security teams to understand what is happening in the landscape and how it translates to impacts on their organizations.
Beyond indicators of compromise (IOCs), ATT&CK allows defenders to visualize threat behaviors in a digestible way to show what TTPs are observed and impacting an organization versus what stakeholders expect or want to focus on.
Analysts can create mappings of MITRE ATT&CK to malware, malware families and techniques observed in their environment. Subsequently, analysts can craft search queries to help with threat hunting and detection efforts. For example, mapping and searching on specific execution techniques such as certutil or BITSAdmin which are being used to download follow-on payloads.
By identifying the most impactful behaviors, and possible gaps in defense, security teams can prioritize hunting, detection, and response based on observable threat behaviors rather than requests or knee-jerk reactions from stakeholders.
Ultimately, Pinkerton’s analysis failed his organization — his reporting coupled with McClellan’s ego and general aversion to taking decisive action may have cost the Union military successes early on in the Civil War.
Reporting Is Not Letter Writing
In addition to some reports containing easily disproved inaccuracies, Pinkerton and many of his staff typically wrote very long reports, with much of the key details hidden among flowery language, tens of pages deep. Effectively communicating actionable intelligence is a common issue with cyber threat intelligence dissemination, and it’s nice to know our predecessors experienced similar flaws.
“He always wrote [intelligence reports] in the form of a letter, and they began with a flowery opening officers of the day commonly used, such as ‘I have the honor to report…’” Lincoln’s Spies
Pinkerton also reportedly doodled in the margins, drawing cartoon fingers to indicate what the most important parts of the reports were.
Succinctly and effectively communicating intelligence through written reports is difficult, but there are some key characteristics of good intelligence reporting that can help improve efficiency, streamline the writing process, and provide stakeholders with relevant data.
Put the most important information first.Frequently referred to as the stating Bottom Line Up Front (BLUF), immediately detailing the findings of your reporting and why they matter to an organization is crucial. This can be considered the “So What?” portion of the report. Most people — especially key stakeholders like executive audiences — will not read every word of an in-depth intelligence report. It is therefore important to ensure that in the short amount of time allotted for consuming reporting, they can read and understand the points that matter most.
Be concise. Pinkerton didn’t need flowery language and neither do you. I have said this before, but I firmly believe people should not require a thesaurus to read and understand threat intelligence reporting. The report should contain relevant information such as: What happened, why does it matter, and what can we do about it? Items such as anecdotes, extraneous clauses, and navel-gazing are generally unnecessary.
Consider your audience.Executives likely don’t need details of deconstructed malware. Security operations analysts likely don’t need geopolitical analysis of events occurring in places where the business does not operate. Threat intelligence analysts should always be aware of who is reading reports and why. Make sure you know the answer to: What decisions are being made based on this data? Gathering intelligence requirements and understanding how your audience is using intelligence throughout the organization can help shape and improve your reporting.
MITRE ATT&CK has become the universal framework for threat actor TTPs, and can be used to quickly distill and communicate threat intelligence. But where and how it’s used varies based on the audience receiving the information.
For example, in February 2022, intelligence agencies from the United States and United Kingdom published a joint advisory on a new malware called Cyclops Blink targeting small office/home office routers attributed to the Russian state actor Sandworm. The 10-page advisory was designed as an overview of the malware and related threats, documenting Sandworm’s historic and current activity and its relevance in the overall threat landscape. In this report, the MITRE ATT&CK mappings were presented at the end, to add additional insight and technical details to an otherwise fairly high-level, strategic report. However, in a companion malware analysis report published by the UK’s National Cyber Security Centre, the ATT&CK mappings were presented on page three of 20, demonstrating the framework can be used to summarize tactical threat intelligence.
Like any tool, where and how you use MITRE ATT&CK to document TTPs is crucial for an audience’s understanding of the threats.
Always Evaluate OSINT
While Pinkerton collected massive amounts of information and distributed it whole cloth to his superiors, there was little explanation given to where the information came from or its validity.
“Rarely did Pinkerton include in his reports an evaluation of a source’s reliability beyond a general impression he had of it.” Lincoln’s Spies
Pinkerton was operating based on human intelligence, information collected by his operatives in the field. Much of it was gossip; some of it reached his ears by a convoluted game of telephone. A lot of it was reliable and accurate — some of it was not.
As intelligence analysts, understanding and evaluating the veracity of information is crucial to communicating and acting on it. Primary sources of intelligence — the data we collect on our networks — we typically understand to be reliable. But we also rely on open source intelligence (OSINT) to form a whole picture of adversary threat behaviors and an understanding of the threat landscape.
Unfortunately, there is a lot of bad information on the internet. The online claims of unconfirmed hacking campaigns during the ongoing war in Ukraine is an excellent example of information spreading far and wide without validation, and likely making it into intelligence briefings on the conflict.
There are multiple questions analysts should ask themselves when reviewing third-party data to support original research, for example:
What is the visibility of the individual or organization?
What evidence are their claims based on?
Is this evidence available to me?
Does this overlap with known threat activity?
Cui bono? Or, who benefits and how?
There is always inherent bias in visibility; vendors or anti-virus companies will only have data from the organizations and geographies in which it is used. If the visibility is limited, it might not be an effective source for verifying or supporting existing hypotheses. Being able to independently validate or invalidate evidence provided in open-source artifacts with internal tools and resources can help further your own investigations or reporting. And finally, considering political, financial, economic, etc. motivations in external reporting can help identify potential biases in reporting and inform your assessments of a source’s reliability.
The MITRE ATT&CK framework exists in part to help answer these questions, especially for providing validated, authoritative third-party intelligence reporting.
A Dictionary of Threats
While the United States was fighting the bloodiest war in the nation’s history, an idea was blossoming among philologists in the United Kingdom. English speakers had colonized many parts of the world, with English customs and culture forcing itself into existing cultures and communities, with paltry existing resources standardizing vocabulary. Academics in the UK argued that there should be a single authoritative resource to define the English language, documenting and establishing the correct form of communications.
Formally proposed in 1857, what would become known as the Oxford English Dictionary would eventually achieve its goal of standardizing English words beginning in 1884. It was a massive undertaking that brought together academics, historians, and the English-speaking public to collect and define words. In fact, the dictionary could not have been written without considerable public assistance.
The MITRE ATT&CK framework has become the universal dictionary of TTPs, in large part due to contributions from analysts and researchers around the globe. According to MITRE, 155 people contributed to the framework in 2021. (In fact, this year my Proofpoint colleague Michael Raggi contributed an update to ATT&CK Technique T1221 to include a novel RTF template injection technique observed in use by multiple threat actors.)
The authoritative nature of the framework has allowed analysts to verify open-source reporting, and better understand the nature of threat actors. It has also allowed researchers to more effectively document and communicate threat behaviors, prioritize detections, and improve defense. By standardizing how we identify and classify threat behaviors, actionable intelligence can be more easily communicated to a variety of stakeholders.
Pinkerton did not have a reliable threat intelligence framework or dictionary off which to operate; indeed he was trailblazing the creation of a secret service that had never before existed. And while his early work helped pave the way for modern day spying and the development of the Secret Service, he and his team were far from perfect. But by examining the intelligence reporting failures documented by modern historians, threat intelligence analysts can be better prepared when they too one day may be called on to help change the course of history.
With the huge rise in critical work data on smartphones over the past couple of years, mobile security is more important than ever before. With this in mind, since early 2021 we’ve been re-designing and rewriting the entirety of ATT&CK for Mobile. We’ve also spent a lot of time considering how we want to continue to enhance Mobile moving forward, including increasing community understanding of the mobile threat landscape.
ATT&CK for Mobile Redux
To start out with, we’d like to take this opportunity to (re)introduce ATT&CK for Mobile, by walking through why it exists, how it’s a bit different from ATT&CK for Enterprise, and what’s coming in 2022.
Mobile devices, which we currently scope to smartphones and tablets running Android, iOS, or iPadOS, are almost always powered on, ubiquitously connected to a variety of networks, contain a vast array of sensors, and run a diverse set of applications. While these properties make mobile devices incredibly useful, they also bring significant security threats.
The security architectures featured on mobile devices are based on lessons learned from the traditional PC environment, notably by providing application sandboxes and permission controls. These architectures provide significant security advantages, but threats still exist against mobile devices. The same detection and mitigation approaches used in enterprise PC environments often don’t work in the mobile environment and alternate approaches have to be leveraged. When ATT&CK for Mobile was publicly released in 2017, the goal was to provide those alternate detection and mitigation approaches, and to serve as dedicated resource to the broader mobile community.
Matrix Structure
Like ATT&CK for ICS, and ATT&CK for Enterprise, ATT&CK for Mobile is a Domain in ATT&CK, with its own separate matrix and content. Despite this separation, Mobile’s matrix still leverages ATT&CK for Enterprise’s structure, just with a distinctly Mobile flavor. ATT&CK for Mobile currently features 92 techniques, each with Android and/or iOS (and iPadOS) specific descriptions, procedures, detections, and mitigations. Mobile also shares the same Software and Groups sections as ATT&CK for Enterprise, but with limited overlap between the Enterprise and Mobile entries.
Leveraging Mobile
The Mobile matrix can be operationalized for many of the same use cases as Enterprise ATT&CK. Some of the use cases we’ve seen include:
Determining and prioritizing development coverage of defensive capabilities
Identifying commonalities and distinguishing characteristics in adversary tradecraft
Connecting mitigations, weaknesses, and adversaries
Determining effective security testing strategies
Evaluating mobile security products with adversary emulations
Assessing the security posture of mobile devices
Additionally, with many organizations adopting ATT&CK for Mobile within theirpublicthreatintelligencereporting, we’re seeing it being used more frequency as a common language to describe adversary behavior. We’re also aware of ATT&CK for Mobile being used internally within vendors’ threat intelligence teams to categorize observations, as well as by vendors to map their mobile security product capabilities.
2022 ATT&CK for Mobile Roadmap
Now that you’ve had a Mobile refresher, we’d like to highlight what’s next in 2022. We noted these in the mobile section of the ATT&CK 2022 Roadmap, but wanted to spend some more time on the details given the size of the changes coming.
Sub-Techniques
The mobile team has been refactoring and rewriting ATT&CK for Mobile over the last several months, with the goal of content equity with Enterprise. This included the language contained within the Mobile techniques themselves, as well as mobile-specific mitigations and detections. Most significantly, we’ve also been working towards the sub-technique structure Enterprise introduced a couple of years ago.
We plan on releasing a beta version of Mobile sub-techniques in April 2022 with the ATT&CK v11 release. Similar to Enterprise’s sub-technique rollout, we will be providing a crosswalk from old technique IDs to new technique IDs or mapping newly broken-out sub-techniques to higher level techniques. This should minimize the overhead incurred when transitioning to the new sub-technique structure.
The sub-technique beta release will be published on a separate website alongside the main ATT&CK website, clearly charting out the changes. This companion site will give the community a couple of months to preview, process, and provide feedback on the full scope of the changes before we finalize that version and make it official. Once we release the new ATT&CK for Mobile framework with sub-techniques, we welcome your feedback on the good, the bad, and the needs-adjustments. When we’re finished working through the input we receive from the community, we expect to replace the current matrix with the sub-technique structure by Summer 2022.
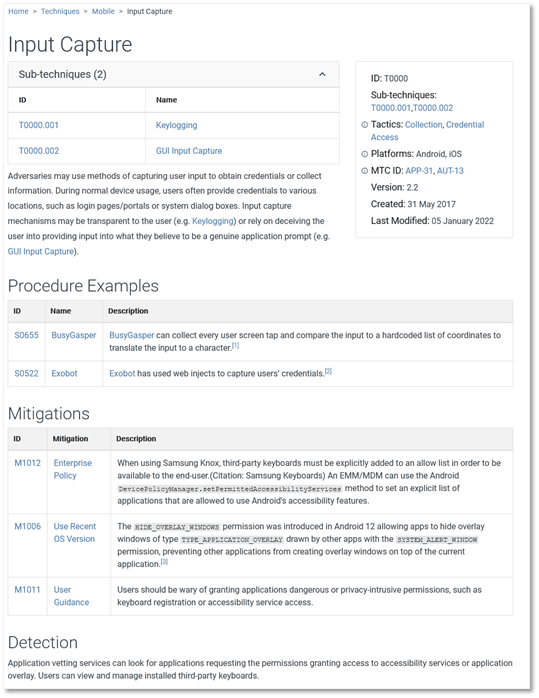
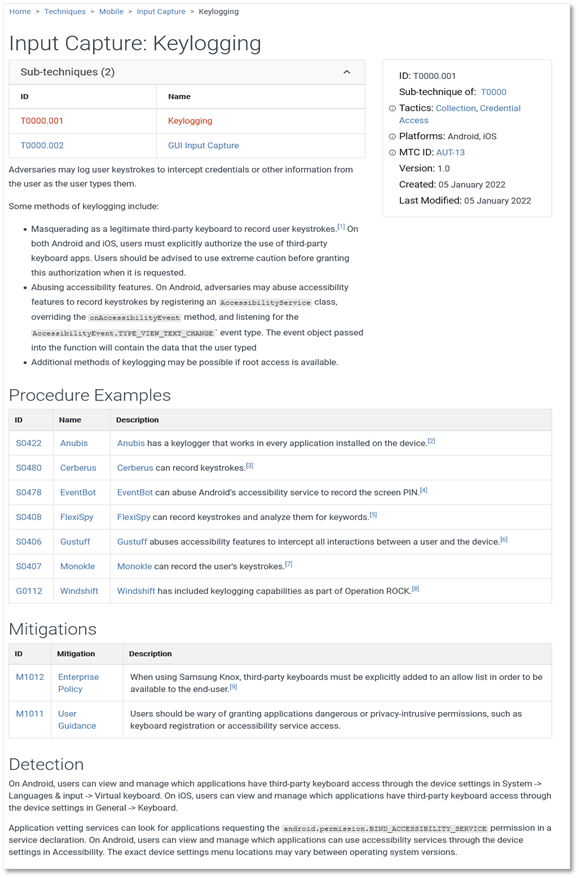
The screenshots below show a sample parent technique and two sub-techniques: Input Capture, Keylogging (sub), and GUI Input Capture (sub).
Data Sources
Once our sub-techniques are released, we’ll pivot to researching and drafting plans to introduce Data Source objects to Mobile, mirroring the concept of Data Source objects that Enterprise recently published. Some examples of mobile-specific Data Sources could include:
Application Binaries
Attestation APIs
Network Traffic
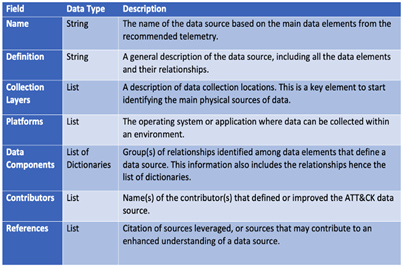
The new metadata provided by data sources includes the concepts of relationships and data components. These concepts will more effectively represent adversary behavior from a data perspective and will provide an additional sub-layer of context to data sources. Data components narrow the identification of security events, but also create a bridge between high- and low-level concepts to inform data collection strategies. They’ll also provide a good reference point to start mapping telemetry collected in your environment to specific sub(techniques) and/or tactics. With the additional context around each data source, the results can be leveraged with more detail when defining data collection strategy for techniques and sub-techniques.
Mobile Threat Awareness Building
Building on the criticality of a collective community understanding of Mobile threats, we kicked off a mini-series back in 2021 highlighting significant threats to mobile devices, starting with abuse of Android application permissions. We plan to continue the series this year, underscoring some of the key mobile threats, and how to use ATT&CK for Mobile to mitigate them.
In Closing
Mobile’s matrix of adversary behavior has continued to grow with each new ATT&CK content release, in strong part due to the contributions we receive. ATT&CK for Mobile is an evolving effort and our goal is to continue to improve and mature the it. We rely on the mobile security community to share data and validate our content and look forward to collaborating with you to ensure the matrix remains beneficial.
We always welcome feedback on ATT&CK for Mobile, including how you view Mobile and Enterprise security together, and where we can improve. You can check out our Contributions page for additional information, or connect with us via email, Twitter, or Slack.
We have several exciting adjustments to the framework on the horizon for 2022, and while we will be making some structural changes this year (Mobile sub-techniques and the introduction of Campaigns), it won’t be nearly as painful as the addition of Enterprise sub-techniques in 2020. In addition to Campaigns and Mobile subs, our key adjustments this year include converting detections into objects, innovating how you can use overlays and combinations, and expanding ICS assets. We plan on maintaining the biannual release schedule of April and October, with a point release (v11.1) for Mobile sub-techniques.
ATT&CKcon 3.0 | March 2022
Your wait is finally over for ATT&CKCon, and we’re thrilled to be hosting it in McLean, VA on March 29–30. We welcome you to join the ATT&CK team and those across the community to hear about all the updates, insights, and creative ways organizations and individuals have been leveraging ATT&CK. We’ll be live streaming the full conference for free and you can find all of the latest details and updates on our ATT&CKcon 3.0 page.
Detection Objects | April & October 2022
Over the past few years, transforming various actionable ATT&CK fields into managed objects has been a reoccurring theme. In v5 of ATT&CK, we converted mitigations into objects to enhance their value and usability — with this conversion, you can now identify a mitigation and pivot to various techniques it can potentially prevent. This has been a feature that many of you have leveraged to map ATT&CK to different control/risk frameworks. We also converted data sources to objects for the v10 release, enabling similar pivoting and analysis opportunities.
Next, we plan on implementing a parallel approach for detections, taking the currently free text featured in techniques, and refining and merging them into descriptions that are connected to data sources. This will enable us to describe for each technique what you need to collect as inputs for that detection (data sources), as well as how you could analyze that data to identify a given technique (detection).
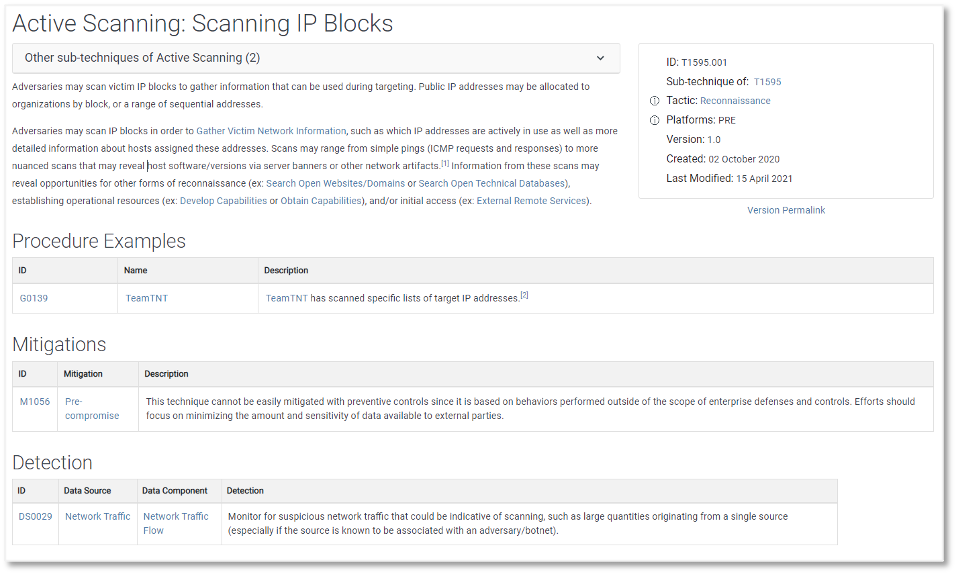
Figure 1: Example ATT&CK technique (T1595.001 Active Scanning: Scanning IP Blocks) showing a draft of the complete Data Sources to Data Components to Detections mappings.
Campaigns | October 2022
One of the more significant changes you can expect this year is the introduction of Campaigns. We define campaigns as a grouping of intrusion activity conducted over a specific period of time with common targets and objectives; this activity may or may not be linked to a specific threat actor. The Solar Winds cyber intrusion, for instance, would become a campaign attributed to the G0016 threat group in ATT&CK. In ATT&CK’s existing structure, all activity for a given threat actor is combined under a single Group entry, making it challenging to accurately see trends, understand how a threat actor has evolved over time (or not), identify the variance between different events, or, conversely, identify certain techniques that an actor may rely on.
In ATT&CK, we’ve never added activity as a Group that hasn’t been given a name by someone else. For example, if a report describes the behaviors of a group or campaign, but never gives that intrusion activity a unique name like FUZZYSNUGGLYDUCK/APT1337 (or links it to someone else’s reporting that does), we wouldn’t incorporate that report into ATT&CK. With the introduction of Campaigns we’ll start including reports that leave activity unnamed and use our own identifiers (watch out for Campaign C0001). On the flip side, this new structure will let us better manage activity where too many things have been given the same name (e.g., Lazarus), providing us a way to tease apart activity that shouldn’t have been grouped together. Finally, we’ll be able to better address intrusion activity where multiple threat actors may be involved, such are Ransomware-as-a-Service operations.
We’re still working to best determine how Campaigns and associated IDs will be displayed in ATT&CK and will provide additional detail in the coming months. Group and Software pages will mostly remain unchanged — they’ll still feature collective lists of techniques and sub-techniques so network defenders can continue to create overall associated Navigator layers and conduct similar analysis. However, we’ll be adding Campaign links to the associated Group/Software pages. We’ll be providing additional details later in the year, as we prepare to integrate Campaigns as part of the October release.
Mobile | April 2022
We’ve been talking about Mobile sub-techniques for a while, and we’re thrilled to say that they’re almosthere. The Mobile team was hard at work in 2021, bringing ATT&CK for Mobile into feature equity with ATT&CK for Enterprise, including identifying where sub-techniques would fit into the Mobile matrix. As we covered in our October 2021 v10 release post, the Mobile sub-techniques will mirror the structure of the Enterprise sub-techniques to address granularity levels. We’ll be including a beta version of the sub-techniques, similar to what we did with Enterprise, for community feedback as part of the April ATT&CK v11 release. We plan on publishing the finalized sub-techniques in a point release (e.g., v11.1), and we’ll include more details about the subs process and timeline in our April release post. In addition to sub-techniques, we’ll be working on a concept for Mobile data source objects, and reigniting our mini-series highlighting significant threats to mobile devices that we kicked off last year. As always, we remain very interested in adversary behavior targeting mobile devices, so if you would like to help us create new techniques, or if you have observed behaviors you’d like to share, reach out to us.
Finally, stay tuned for the ATT&CK for Mobile 2022 Roadmap that will be arriving soon. While we don’t typically publish separate roadmaps for technology domains, Mobile needs some additional space this year to cover the updates and planned content changes.
MacOS and Linux | April & October 2022
We made many adjustments, additions, and content updates to the macOS and Linux platforms last year, with a focus on macOS. For 2022 we hope to maintain the macOS momentum while transitioning our focus to updating Linux. Our April release will center around resolving several macOS contributions from last year. These updates include broadening the scope of parent techniques to include additional platforms, adding sub-techniques, updating procedures with specific usage examples, and supporting the data sources + detection efforts. We will continue to update macOS throughout the year and greatly appreciate the community engagement and all of the contributors that have enabled us to better represent this platform.
The April release will also feature revised language and platform mapping for Linux. We’re aiming for an improved representation of Linux within ATT&CK for all techniques by our October release. Although Linux is frequently leveraged by adversaries, public reporting is often scarce on detail making this a challenging platform for ATT&CK. Our ability to describe this space is closely tied to those of you in the Linux security community, and we hope to engage and establish more connections with you over the next several months. If you’re interested in sharing any observed activities or suggestions for techniques, please reach out and let us know.
ICS | October 2022
We updated our ICS content and data sources in 2021, and over the next several months, we’ll be expanding ICS Assets and adding detections. Asset names are tied to specific ICS verticals (e.g., electric power, water treatment, manufacturing), and the associated technique mappings enable users to understand if and how techniques apply to their environments. In addition, more granular asset definitions will help to highlight similarities and differences in functionality across technologies and verticals. The detections we’ll be adding to each technique will provide guidance on how the recently updated data sources can be used to identify adversary behavior. Finally, we’re preparing to integrate ICS onto the same platform as Enterprise and join the rest of the domains on the ATT&CK website (attack.mitre.org) later this year.
Overlays and Combinations | October 2022
Throughout the next several months, we’ll continue moving towards developing and sharing ideas for overlays and combinations, or how you can pull various ATT&CK platforms and domains together into a specialized view of ATT&CK. Using Linux and Containers together, for example, or integrating security across Enterprise and Mobile, or between Enterprise and ICS. Our goal with this effort is to provide the tools and resources for the community to leverage the various spaces of ATT&CK, and tailor them to their security needs.
Connect With Us!
ATT&CK will always be community-driven and our continued impact hinges on our collaboration with all of you. Your on-the-ground experience and input enables us to continue to evolve and we look forward to connecting with you on email, Twitter, or Slack.
ATT&CK 2022 Roadmap was originally published in MITRE ATT&CK® on Medium, where people are continuing the conversation by highlighting and responding to this story.
As announced a couple of weeks ago, we’re back with the latest release and we’re thrilled to reveal all the updates and features waiting for you in ATT&CK v10. The v10 release includes the next episode in our data sources saga, as well as new content and our usual enhancements to (sub-)Techniques, Groups, and Software across Enterprise, Mobile and ICS, which you can find more details about on our release notes.
Making Sense of the New Data Sources: Episode II
In ATT&CK v9, we launched the new form of data sources which featured an updated structure for the data source names (Data Source: Data Component), reflecting
“What is the subject/topic of the collected data (file, process, network traffic, etc.)?” :
“What specific values/properties are needed in order to detect adversary behaviors?”
These updates were linked to Yaml files in GitHub, but weren’t fully integrated into the rest of ATT&CK yet. Our updated content in ATT&CK v10 aggregates this information about data sources, while structuring them as the new ATT&CK data source objects (somewhat similar to how Mitigations are reflected).
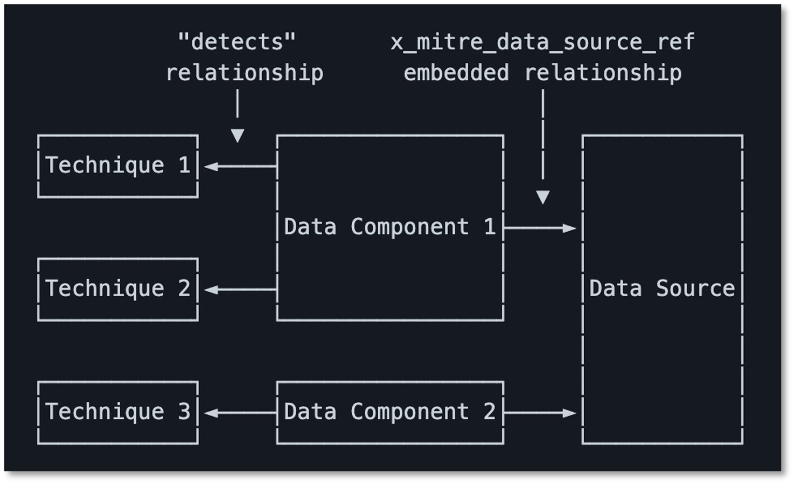
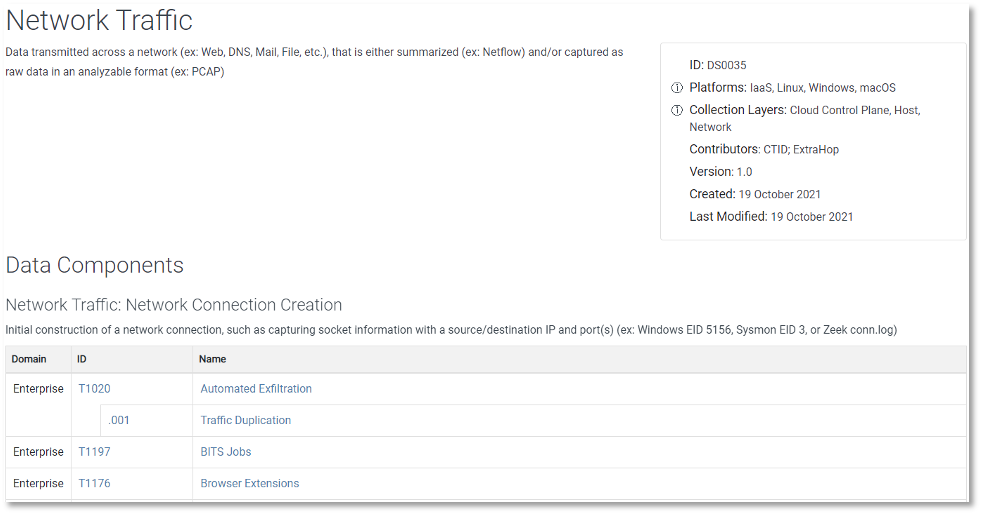
The data source object features the name of the data source as well as key details and metadata, including an ID, a definition, where it can be collected (collection layer), what platform(s) it can be found on, and the data components highlighting relevant values/properties that comprise the data source. Featured below is an example of a data source page in ATT&CK v10.
Figure 1: Network Traffic Data Source Page
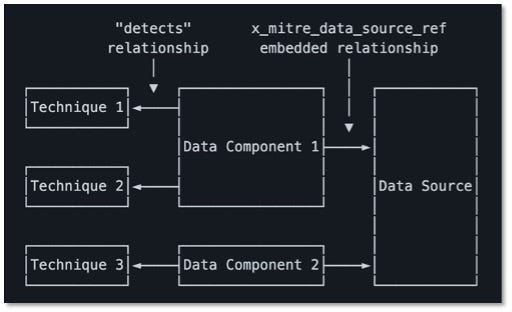
Data Components are also listed below, each highlighting mappings to the various (sub-)techniques that may be detected with that particular data. On individual (sub-)techniques, data sources and components have been relocated from the metadata box at the top of the page to be collocated with Detection content.
Figure 2: New Data Source Placement on Technique (T1055.001) Page
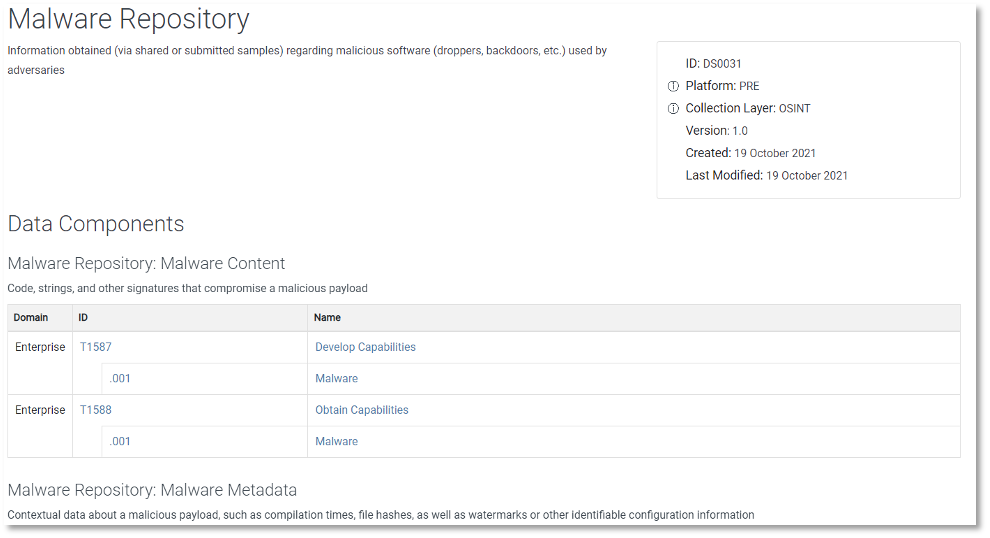
These data sources are available for all platforms of Enterprise ATT&CK, including our newest additions that cover OSINT-related data sources mapped to PRE platform techniques.
Figure 4: Malware Repository Data Source Page
These updated structures are also visible in ATT&CK’s STIX representation, with both the data sources and the data components captured as custom STIX objects. You’ll be able to see the relationships between those objects, with the data sources featuring one or more data components, each of which detects one or more techniques. For more information about ATT&CK’s STIX representation, including these new objects and relationships, you can check out our STIX usage document.
Figure 5: Data Source STIX Model
We hope that these enhancements further increase our ability to translate our understanding of the adversary behaviors captured within ATT&CK to the data we collect as defenders. We are very excited to see these data source objects grow and evolve, and like the rest of ATT&CK, invite the community to submit contributions and feedback!
Note: We will no longer be working with Enterprise data sources in GitHub after ATT&CK v10. Moving forward we will accept all related contributions through our normal contribution process.
MacOS and Linux: Now with New Content!
Over the past several months, we’ve been continuing to improve and expand coverage across the macOS and Linux platforms. We understand adversaries actively target these platforms, however there is significantly less public reporting for adversarial hands-on-keyboard procedures and malware analysis. We’re pleased to report that we’ve been collaborating with macOS security and vulnerability research contributors across the globe to address these challenges. In upcoming releases, we’re hoping to leverage this same community engagement for Linux. We’re excited to see the growth in content from the community’s contribution, and the improvements ranging from how we capture new techniques to conveying the impact of existing techniques was a collaborative effort.
One of the most notable changes we made for techniques across the board was providing more in-depth references and use-cases on how procedures and processes work, and the impact they have. Remote services along with additional techniques for macOS and Linux received some attention, but most improvements were more detailed examples in the description section with supporting detection ideas. Along with the rest of Enterprise, we also updated our macOS data sources to enhance defender visibility.
ICS: Object-Oriented and Integrating
ICS has been focusing on feature equity with Enterprise, including updating data sources, adding and refining techniques, revamping assets, and charting out our detections plan. We’re also making some key changes to facilitate hunting in ICS environments. As we noted in the 2021 Roadmap, v10 also includes cross-domain mappings of Enterprise techniques to software that were previously only represented in the ICS Matrix, including Stuxnet, Industroyer, and several others. The fact that adversaries don’t respect theoretical boundaries is something we’ve consistently emphasized, and we think it’s crucial to feature Enterprise-centric mappings for more comprehensive coverage of all the behaviors exhibited by the software. With Stuxnet and Industroyer specifically, both malware operated within OT/ICS networks, but the two incidents displayed techniques that are also well researched and represented within the Enterprise matrix. Based on this, we created Enterprise entries for the ICS-focused software to provide network defenders with a view of software behavior spanning both matrices. We also expect the cross-domain mappings to enable you to leverage the knowledge bases together more effectively.
For data sources, we’re aligning with Enterprise ATT&CK in updating data source names. ICS’s current release reflects Enterprise’s v9 data sources update, with the new name format and content featured in GitHub. These data sources will be linked to YAML files that provide more detail, including what the data sources are and how they should be used. For future releases we plan on mapping the more granular assets to techniques to enable you to track how these behaviors can affect a technique, or what assets these behaviors are associated with. On the detections front, we’re working behind the scenes to add detections to each technique, and this will be reflected in future releases (we expect detections to really help out in hunt and continuous monitoring). Also in 2022, we’re preparing to integrate onto the same development platform as Enterprise, the ATT&CK Workbench, and join the rest of the domains on the ATT&CK website (attack.mitre.org).
Expanding Our Mobile Features
In the Mobile space, we’ve been focused on catching up on the contributions from the community, updating (sub-)techniques, Groups, and Software, and enhancing general parity with Enterprise. We’ve also been working hard behind the scenes to implement sub-techniques as mentioned in our 2021 Roadmap. We’re excited to introduce this new Mobile structure in April 2022, to better align with other platforms on Enterprise. Our plan is to do a beta release for the sub-techniques prior to the release of v11 to provide you with an opportunity to test out those updates and provide feedback.
About Cloud
Along with the rest of Enterprise, we’ve been updating content across Cloud, collaborating with community members on activity in the Cloud domain, and keeping an eye out for new platforms to add to the space. We also continued working on data sources, although as we outlined for the v9 release, our Cloud data sources are a little different than the host-based data sources, specifically aligning more with the events and APIs involved in detections instead of just focusing on the log sources.
What’s Next in 2022?
We hope you’re as excited as we are about v10, and we’d love your feedback and for you to join us in shaping our v11 release. We already have a lot on the horizon for 2022, included structured detections, campaigns, tools to enable overlays and combinations, and ATT&CKcon. If you have feedback, comments, contributions, or just want to ask questions, connect with us on email, Twitter, or Slack.