
Simple Scaling Policies
With a simple scaling policy, whenever the metric rises above the threshold, Auto Scaling simply increases the desired capacity. How much it increases the desired capacity, however, depends on which of the following adjustment types you choose:
ChangeInCapacity Increases the capacity by a specified amount. For instance, you start with a desired capacity of 4 and then have an Auto Scaling add 2 when the load increases.
ExactCapacity Sets the capacity to a specific value, regardless of the current value. For example, suppose the desired capacity is 4. You create a policy to change the value to 6 when the load increases.
PercentChangeInCapacity Increases the capacity by a percentage of the current amount. If the current desired capacity is 4 and you specify the percent change in capacity as 50 percent, then Auto Scaling will bump the desired capacity to 6. For example, suppose you have four instances and create a simple scaling policy that specifies a PercentChangeInCapacity adjustment of 50 percent. When the monitored alarm triggers, Auto Scaling will increment the desired capacity by 2, which will in turn add 2 instances to the auto scaling group, giving a total of 6. After Auto Scaling completes the adjustment, it waits a cooldown period before executing the policy again, even if the alarm is still breaching. The default cooldown period is 300 seconds, but you can set it as high as you want or as low as 0—effectively disabling it. Note that if an instance is unhealthy, Auto Scaling will not wait for the cooldown period before replacing the unhealthy instance.
Referring to the preceding example, suppose after the scaling adjustment completes and the cooldown period expires, the monitored alarm drops below the threshold. At this point, the desired capacity is 6. If the alarm triggers again, the simple scaling action will execute again and add three more instances. Keep in mind that Auto Scaling will never increase the desired capacity beyond the group’s maximum setting.
Step Scaling Policies
If the demand on your application is rapidly increasing, a simple scaling policy may not add enough instances quickly enough. Using a step scaling policy, you can instead add instances based on how much the aggregate metric exceeds the threshold. To illustrate, suppose your group starts out with four instances. You want to add more instances to the group as the average CPU utilization of the group increases. When the utilization hits 50 percent, you want to add two more instances. When it goes above 60 percent, you want to add four more instances. You’d first create a CloudWatch Alarm to monitor the average CPU utilization and set the alarm threshold to 50 percent, since this is the utilization level at which you want to start increasing the desired capacity. You’d must then specify at least one step adjustment. Each step adjustment consists of the following:
■ A lower bound
■ An upper bound
■ The adjustment type
■ The amount by which to increase the desired capacity
The upper and lower bound define a range that the metric has to fall within for the step adjustment to execute. Suppose for the first step you set a lower bound of 50 and an upper bound of 60, with a ChangeInCapacity adjustment of 2. When the alarm triggers, Auto Scaling will consider the metric value of the group’s average CPU utilization. Suppose it’s 55 percent. Because 55 is between 50 and 60, Auto Scaling will execute the action specified in this step, which is to add two instances to the desired capacity. Suppose now that you create another step with a lower bound of 60 and an upper bound of infinity. You also set a ChangeInCapacity adjustment of 4. If the average CPU utilization increases to 62 percent, Auto Scaling will note that 60 <= 62 < infinity and will execute the
action for this step, adding 4 instances to the desired capacity. You might be wondering what would happen if the utilization were 60 percent. Step ranges
can’t overlap. A metric of 60 percent would fall within the lower bound of the second step. With a step scaling policy, you can optionally specify a warm-up time, which is how long Auto Scaling will wait until considering the metrics of newly added instances. The default warm up time is 300 seconds. Note that there are no cooldown periods in step scaling policies.
Target Tracking Policies
If step scaling policies are too involved for your taste, you can instead use target tracking policies. All you do is select a metric and target value, and Auto Scaling will create a CloudWatch Alarm and a scaling policy to adjust the number of instances to keep the metric near that target. The metric you choose must change proportionally to the instance load. Metrics like this include average CPU utilization for the group and request count per target. Aggregate metrics
like the total request count for the ALB don’t change proportionally to the load on an individual instance and aren’t appropriate for use in a target tracking policy. Note that in addition to scaling out, target tracking will also scale in by deleting instances to maintain the target metric value. If you don’t want this behavior, you can disable scaling in. Also, just as with a step scaling policy, you can optionally specify a warm-up time.
Scheduled Actions
Scheduled actions are useful if you have a predictable load pattern and want to adjust your capacity proactively, ensuring you have enough instances before demand hits. When you create a scheduled action, you must specify the following:
■ A minimum, maximum, or desired capacity value
■ A start date and time
You may optionally set the policy to recur at regular intervals, which is useful if you have a repeating load pattern. You can also set an end time, after which the scheduled policy gets deleted.
To illustrate how you might use a scheduled action, suppose you normally run only two instances in your Auto Scaling group during the week. But on Friday, things get busy, and you know you’ll need four instances to keep up. You’d start by creating a scheduled action that sets the desired capacity to 2 and recurs every Saturday, as shown in Figure 9.1.
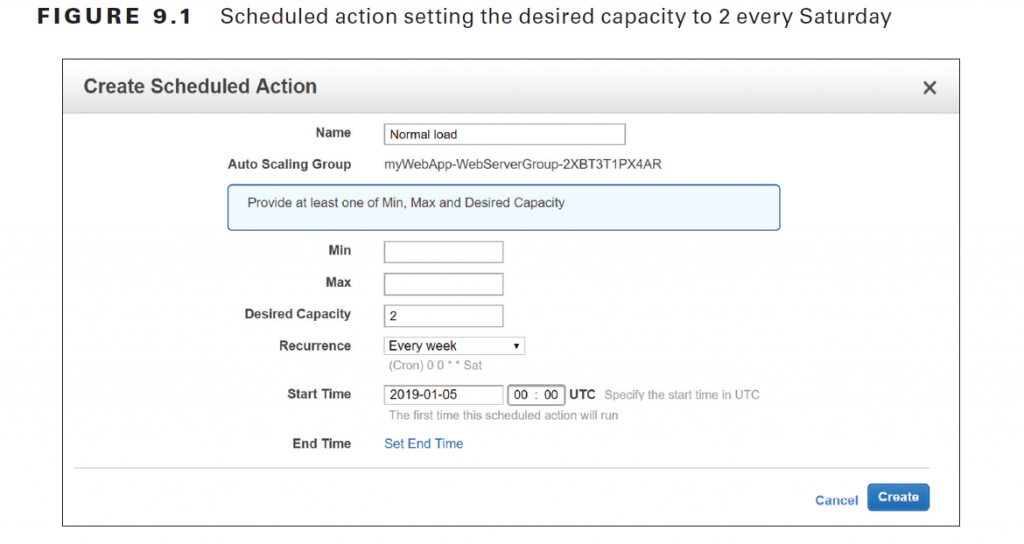
The start date is January 5, 2019, which is a Saturday. To handle the expected Friday spike, you’d create another weekly recurring policy to set the desired capacity to 4, as shown in Figure 9.2.
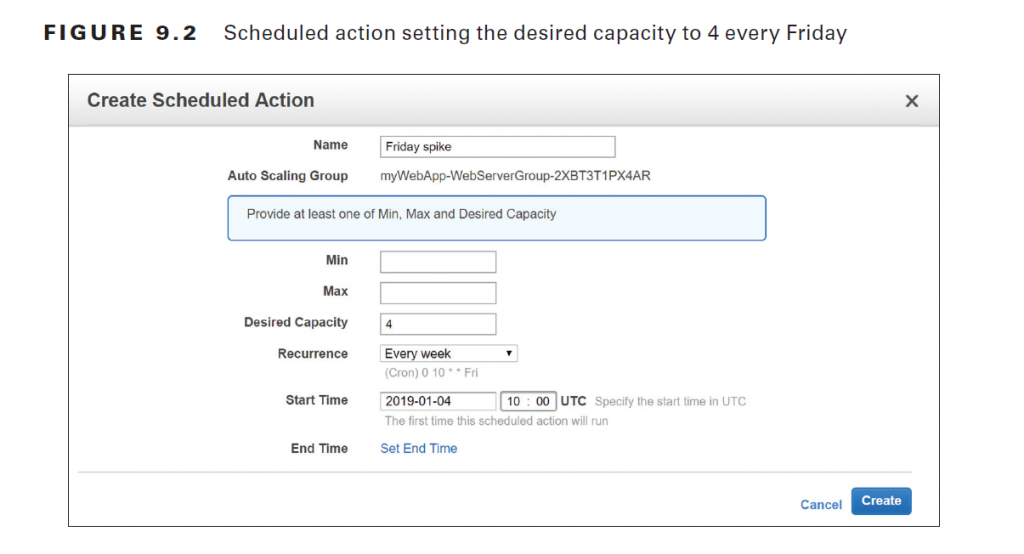
This action will run every Friday, setting the desired capacity to 4, prior to the anticipated increased load. Note that you can combine scheduled actions with dynamic scaling policies. For example, if you’re running an e-commerce site, you may use a scheduled action to increase the maximum group size during busy shopping seasons and then rely on dynamic scaling policies to increase the desired capacity as needed.
Data Backup and Recovery
As you learned in Chapter 2, “Amazon Elastic Compute Cloud and Amazon Elastic Block Store,” and Chapter 3, “Amazon Simple Storage Service and Amazon Glacier Storage,” AWS offers several different data storage options. Although Amazon takes great pains to ensure the durability of your data stored on these services, data loss is always a possibility. AWS offers several options to help you store your data in a resilient manner as well as maintain backups to recover from when the inevitable data loss occurs.
S3
All S3 storage classes except One Zone-Infrequent Access distribute objects across multiple availability zones. To avoid data loss from the failure of a single availability zone, be sure to use one of the other storage classes. To guard against deletion and data corruption, enable S3 versioning. With versioning
enabled, S3 never overwrites or deletes an object. Instead, modifying an object creates a new version of it that you can revert to if needed. Also, instead of deleting an object, S3 inserts a delete marker and removes the object from view. But the object and all of its versions still exist. To protect your data against multiple availability zone failures—or the failure of an entire region—you can enable cross-region replication between a source bucket in one region and destination bucket in another. Once enabled, S3 will synchronously copy every object from the source bucket to the destination. Note that cross-region replication requires versioning to be enabled on both buckets. Also, deletes on the source bucket don’t get replicated.
Elastic File System
AWS Elastic File System (EFS) provides a managed Network File System (NFS) that can be shared among EC2 instances or on-premises servers. EFS filesystems are stored across multiple zones in a region, allowing you to withstand an availability zone failure. EFS doesn’t come with versioning or native backup/restore capability. To protect against data loss and corruption, you can back up individual files to an S3 bucket or another EFS filesystem in the same region.
Elastic Block Storage
EBS automatically replicates volumes across multiple availability zones in a region so they’re resilient to a single availability zone failure. Even so, data corruption is always a possibility.
One of the easiest ways to back up an EBS volume is to take a snapshot of it. AWS stores EBS snapshots across multiple availability zones in S3. You can either create a snapshot manually or use the Amazon Data Lifecycle Manager to automatically create a snapshot for you at regular intervals. To use the Amazon Data Lifecycle Manager, you create a Snapshot Lifecycle Policy and specify an interval of 12 or 24 hours, as well as a snapshot creation time. You also must specify the number of automatic snapshots to retain, up to 1,000 snapshots. One important but often overlooked piece of data that gets stored on EBS is application logs. An application may create log files on the instance it’s running on, but if the instance crashes or loses connectivity, those files won’t be able to tell you what’s wrong. And if EC2 Auto Scaling terminates an instance and its EBS volume along with it, any log files stored locally are gone permanently. CloudWatch Logs can collect and store application logs from an instance in real time, letting you search and analyze them even after the instance is gone.
Also read this topic: Introduction to Cloud Computing and AWS -1
Database Resiliency
When it comes to protecting your databases, your options vary depending on whether you’re using a relational database or DynamoDB. If you’re running your own relational database server, you can use the database engine’s native capability to back up the database to a file. You can then store the file in S3 or Glacier for safekeeping. Restoring a database depends on the particulars of the database engine you’re running but generally involves copying the backup file back to the destination instance and running an import process to copy the contents of the backup file into the database.
If you’re using Amazon Relational Database Service (RDS), you always have the option of taking a simple database instance snapshot. Restoring from a database snapshot can take several minutes and always creates a new database instance. For additional resiliency, you can use a multi-AZ RDS deployment that maintains a primary instance in one availability zone and a standby instance in another. RDS replicates data synchronously from the primary to the standby. If the primary instance fails, either because of an instance or because of availability zone failure, RDS automatically fails over to the secondary. For maximum resiliency, use Amazon Aurora with multiple Aurora replicas. Aurora stores your database across three different availability zones. If the primary instance fails, it will fail over to one of the Aurora replicas. Aurora is the only RDS offering that lets you provision up to 15 replicas, which is more than enough to have one in each availability zone!
DynamoDB stores tables across multiple availability zones, which in addition to giving you low-latency performance also provides additional protection against an availability zone failure. For additional resiliency, you can use DynamoDB global tables to replicate your tables to different regions. You can also configure point-in-time recovery to automatically take backups of your DynamoDB tables. Point-in-time recovery lets you restore your DynamoDB tables to any point in time from 35 days until 5 minutes before the current time.
Creating a Resilient Network
All of your AWS resources depend on the network, so designing your network properly is critical. When it comes to network design, there are two different elements to consider: your virtual private cloud (VPC) design and how users will connect to your resources within your VPC.
VPC Design Considerations
When creating a VPC, make sure you choose a sufficiently large classless interdomain routing (CIDR) block to provide enough IP addresses to assign to your resources. The more redundancy you build in to your AWS deployment, the more IP addresses you’ll need. Also, when you scale out by adding more resources, you must have enough IP addresses to assign to those additional resources. When creating your subnets, leave enough unused address space within the CIDR to add additional subnets later. This is important for a couple of reasons. First, AWS occasionally adds additional availability zones to a region. By leaving additional space, you can take advantage of those new availability zones. Your availability requirements may call for only one availability zone today, but it doesn’t hurt to leave room in case your needs change. Second, even if you don’t ever need an additional availability zone, you may still need a separate
subnet to segment your resources for security or ease of management. When you separate an application’s components into multiple subnets, it’s called a multi-tier architecture. Leave plenty of space in each subnet. Naturally, having more instances will consume more IP addresses. Leave enough free address space in each subnet for resources to use as demand grows. If any of your instances will have multiple private IP addresses, take that into account. Also, remember that EC2 instances aren’t the only resources that consume IP address space. Consider Elastic Load Balancing interfaces, database instances, and VPC
interface endpoints.
External Connectivity
Your application’s availability is dependent upon the availability of the network users use to access it. Remember that the definition of availability is that your application is working as expected. If users can’t connect to it because of a network issue, your application is unavailable to them, even if it’s healthy and operating normally. Therefore, the method your users use to connect to the AWS cloud needs to meet your availability requirements. The most common way to connect to AWS is via the Internet, which is generally reliable, but speed and latency vary and can be unpredictable. If getting to your application is painfully
slow, you may consider it to be unavailable. To get around a slow Internet pipe or for mission-critical applications, you may choose to use Direct Connect, either as a primary connection to AWS or as a backup. If you need a fast and reliable connection to AWS—such as if you’re pushing a lot of data—Direct Connect offers access speeds of 1 or 10 Gbps with consistent latency. As a secondary connection, if you can’t use the Internet to reach your AWS resources, you can get through using Direct Connect. If you’re going to use Direct Connect, VPC peering, or a VPN connection to an external network, make sure your VPC addresses don’t overlap with those used in the external network. Also, be sure to leave enough room to assign IP addresses to virtual private gateways and Direct Connect private virtual interfaces.
Designing for Availability
Understanding all of the different factors that go into architecting for reliability is important. But as an AWS architect, you need to be able to start with an availability requirement and design a solution that meets it. In this section, you’ll learn how to start with a set of application requirements and design different AWS infrastructures to meet three common availability percentages: 99 percent, 99.9 percent, and 99.99 percent. As you might expect, there’s a proportional relationship between availability, complexity, and cost. The higher the availability, the more resources you’re going to need to provision, which adds more complexity and, of course, more cost. Although most organizations want as much availability as possible, you as an AWS architect must strike a balance between availability and cost. Designs with lower availability may appear, from a technical standpoint, to be inferior. But at the end of the day, the needs and priorities of the organization are what matter. In the following scenarios, you’ll architect a solution for a web-based payroll application that runs as a single executable on a Linux EC2 instance. The web application connects to a backend SQL database for storing data. Static web assets are stored in a public S3 bucket. Users connect to the application by browsing to a public domain name that is hosted on Route 53
Designing for 99 Percent Availability
In the first scenario, you’re aiming for 99 percent availability, or about 3.5 days of downtime per year. Downtime is an inconvenience but certainly not the end of the world. In this case, you’ll create a single EC2 instance to run both the application and a selfhosted SQL database. For backing up data, you’ll run a script to automatically back up the database to an S3 bucket with versioning enabled. To keep data sprawl under control, you’ll configure S3 lifecycle policies to move older backups to the Glacier storage class. To alert users during outages, configure a Route 53 health check to monitor the health of the application by checking for an HTTP 200 OK status code. Then create a Route 53 failover record set to direct users to the application when the health check passes and to a static informational web page when it doesn’t. The static web page can be stored in either a public S3 bucket that’s configured for website hosting or a CloudFront distribution.
Recovery Process
It’s important to test your recovery processes regularly so that you know they work and how long they take. Don’t just create a SQL dump and upload it to an S3 bucket. Regularly bring up a new instance and practice restoring a database backup to it. To quickly build or rebuild your combination application/database instance, use CloudFormation to do the heavy lifting for you. Create a CloudFormation template to create a new instance, install and configure the web and database servers, copy application files from a repository, and set up security groups. The CloudFormation template serves two purposes: rebuilding quickly in case of an instance failure and creating a throwaway instance for practicing database restores and testing application updates.
Availability Calculation
When it comes to estimating availability, you’re going to have to make some assumptions. Each failure will require 30 minutes to analyze and decide whether to initiate your recovery process. Once you decide to recover, you’ll use your CloudFormation template to build a new instance, which takes about 10 minutes. Lastly, you’ll restore the database, which takes about 30 minutes. The total downtime for each failure—or your recovery time objective (RTO)—is 70 minutes. Note that the recovery point objective (RPO) you can expect depends on how frequently you’re backing up the database. In this case, assume that your
application will suffer one failure every quarter. That’s a total annual downtime of 280 minutes, or about 4.6 hours. However, that’s just for failures. You also need to consider application and operating system updates. Assuming that updates occur 6 times a year and require 4 hours of downtime each, that’s additional downtime of 24 hours per year. Adding all the numbers together, between failures and updates, the total downtime per year is about 28.6 hours or
1.19 days. That’s 99.67 percent availability! Although it’s tempting to round 99.67 percent up to 99.9 percent, keep in mind that the difference between those two numbers is more than seven hours per year. Providing inflated availability numbers, even if you’re honestly just rounding up, can come back to bite you
if those numbers turn out later to be out of line with the application’s actual availability. Remember that your availability calculations are only as good as the assumptions you make about the frequency and duration of failures and scheduled outages. When it comes to availability, err on the side of caution and round down! Following that advice, the expected availability of the application is 99 percent.
Designing for 99.9 Percent Availability
When designing for 99.9 percent availability, downtime isn’t the end of the world, but it’s pretty close. You can tolerate about 9 hours a year, but anything beyond that is going to be a problem. To achieve 99.9 percent availability, you’ll use a distributed application design. The application itself will run on multiple instances in multiple availability zones in a single region. You’ll configure an ALB to proxy traffic from users to individual instances and perform health checks against those instances. You’ll create a launch template to install the application web server and copy over application files from a centralized repository. You’ll then create an Auto Scaling group to ensure that you always have at least six running instances (two in each zone). Why six instances? Suppose that you need four application instances to handle peak demand. To withstand the loss of one zone, having two instances in each zone ensures they can handle 50 percent of the peak demand. That way, if one zone fails—taking two instances with it—the remaining two zones have four instances, which is enough to handle 100 percent of the load.
Recovery Process
For most failures, recovery will be automatic. You’ll configure the Auto Scaling group to use the ALB’s target health checks to determine the health of each instance. If an instance fails, the ALB will route traffic away from it, and then Auto Scaling will terminate the failed instance and create a new one. For the database, you’ll use a multi-AZ RDS instance. If the primary database instance fails (perhaps because of an entire availability zone failure), RDS will failover to the secondary instance in a different zone. You’ll also configure automated database instance snapshots to guard against database corruption. Enabling automated snapshots also enables point-in-time recovery, reducing your RPO to as little as five minutes.
Availability Calculation
Thanks to the resilience of the redundant, distributed architecture, you expect only two unplanned outage events per year, lasting 60 minutes each. Software and operating system updates occur 10 times a year and last 15 minutes each. Adding up the numbers, you get a total downtime of 270 minutes or 4.5 hours per year. That’s 99.95 percent availability! Again, to be conservative, you want to round that down to 99.9 percent.
Designing for 99.99 Percent Availability
Mission-critical applications, often those that generate a lot of revenue or have a significant impact on human life, must be able to tolerate multiple component failures without having to allocate additional resources. AWS takes great pains to isolate availability zone failures. However, there’s always the possibility that multiple zones in a single region can fail simultaneously. To protect against these regional disruptions, you’ll simultaneously run application instances in two different regions, an active region and a passive region. Just as in the preceding scenario, you’ll use Auto Scaling to provision the instances into multiple availability zones in each region and ensure that each zone can handle 50 percent of the peak load. You’ll also use multi-AZ RDS; however, there’s a catch. The primary and secondary database instances both must run in the same region. RDS doesn’t currently allow you to have a primary database instance in one region and secondary in another. Therefore, there’s no way to failover from one region to the other without the potential for data loss. But you do have another option. If you use the MySQL or MariaDB database engine, you can create a multi-AZ read replica in a different region. You can then asynchronously replicate
data from one region to the other. With this option, there’s a delay between the time data is written to the primary and the time it’s replicated to the read replica. Therefore, if the primary database instance fails before the replication has completed, you may lose data. For example, given a replication lag of 10 minutes, you may lose 10 minutes of data.
Recovery Process
As in the preceding example, for an application or database instance failure isolated to the active region, or even for an entire availability zone failure, recovery is automatic. But regional failures require some manual intervention. Users will access application instances only in the active region until that region fails. You’ll create a CloudWatch Alarm to monitor the health of the ALB in the active region. If the ALB in the active region fails its health check, you must then decide whether to failover to the passive region. If you do choose to failover, you’ll need to do two things. First, you’ll change the Route 53 resource record to redirect users to the ALB in the standby region. Second, you’ll need to promote the read replica in the passive region to be the new primary database instance.
Availability Calculation
Failures requiring manual intervention should be rare and would probably involve either a failure of the active region that requires failover to the passive region or database corruption that requires restoring from a snapshot. Assuming two failures a year, each failure lasting 20 minutes, that amounts to 40 minutes of downtime per year. That equates to just over 99.99 percent availability. Software and operating system updates require no downtime. When you need to do an
update, you simply provision more instances alongside the existing ones. You upgrade the new instances and then gracefully migrate users to the new instances. In the event that an upgrade breaks the application, directing users back to the original instances is trivial and quick.
People also ask this Questions
- What is a defense in depth security strategy how is it implemented?
- What is AWS Solution Architect?
- What is the role of AWS Solution Architect?
- Is AWS Solution Architect easy?
- What is AWS associate solutions architect?
- Is AWS Solutions Architect Associate exam hard?
Infocerts, 5B 306 Riverside Greens, Panvel, Raigad 410206 Maharashtra, India
Contact us – https://www.infocerts.com
