
Optimizing Performance for the Core AWS Services
Through the book’s earlier chapters, you experienced the power and flexibility of Amazon’s compute, storage, database, and networking services. You’ve seen how to tune, launch, and administrate those tools to support your applications, and you’re aware of some of the many configuration options that come built-in with the platform. In this section, you’ll take all that knowledge to the next level. You’ll explore the ways you can apply some key design principles to solve—and prevent—real-world performance problems.
Compute
What, ultimately, is the goal of all “compute” services? To quickly and efficiently apply some kind of compute resource to a workload demand. The key there is “some kind of,” as it acknowledges that not every problem is best addressed by the same kind of compute resource. To get it right, you’ll need to put together just the right blend of functionality and power.
EC2 Instance Types
As you saw in Chapter 2, “Amazon Elastic Compute Cloud and Amazon Elastic Block Store,” the performance you’ll get from a particular EC2 instance type is defined by a number of configuration variables. Your job, when building your deployment, is to match the instance type you choose as closely as possible to the workload you expect to face. Of course, you can always change the type of a running instance if necessary or just add more of the same.
Auto Scaling
Can’t get everything you need from a single EC2 instance? Then feel free to scale out. Scaling out (or scaling horizontally as it’s sometimes called) involves supporting application demand by adding new resources that will run identical workloads in parallel with existing instances. A typical scale-out scenario would involve a single EC2 instance hosting an e-commerce web server that’s struggling to keep up with rising customer demand. The account administrators could take a snapshot of the EBS volume attached to the existing instance and use it to generate an image for a private EC2 AMI. They could then launch multiple
instances using the AMI they’ve created and use a load balancer to intelligently direct customer traffic among the parallel instances. (You’ll learn more about load balancing a bit later in this chapter.) That’s scaling. Auto Scaling is an AWS tool that can be configured to automatically launch or shut down instances to meet changing demand. As demand rises, consuming a predefined percentage of your instance’s resources, EC2 will automatically launch one
or more exact copies of your instance to share the burden. When demand falls, your deployment will be scaled back to ensure there aren’t costly, unused resources running. Auto Scaling groups are built around launch configurations that define the kind of instance you want deployed. You could specify a custom EC2 AMI preloaded with your application (the way you saw in Chapter 2), or you could choose a standard AMI that you provision by passing user data at launch time.
Serverless Workloads
You can build elastic compute infrastructure to efficiently respond to changing environments without using an EC2 instance. Container tools like Docker or code-only functions like Lambda can provide ultra-lightweight and “instant-on” compute functionality with far less overhead than you’d need to run a full server. As you saw in Chapter 2, container management tools like the Amazon Elastic Container Service—and its front-end abstraction AWS Fargate—can maximize your resource utilization, letting you tightly pack multiple fast-loading workloads on a single instance. Containers are also designed to be scriptable so their administration can easily be automated. Unlike EC2 instances or ECS containers, AWS Lambda works without the need to provision an ongoing server host. Lambda functions run code for brief spurts (currently up to 15 minutes) in response to network events. Lambda functions can be closely integrated
with other AWS services including by exposing your function to external Application programming interface (API) requests using Amazon API Gateway.
Storage
You’ve already seen how Elastic Block Store (EBS) volumes provide durable storage where IOPS, latency, and throughput settings determine your data access performance (Chapter 2). You also know about the scalable and multitiered object storage available through S3 and Glacier (Chapter 3 Amazon Simple Storage Service (S3) and Amazon Glacier Storage). Chapter 3 is also where you encountered the Amazon Elastic File System (EFS), which offers shared file storage for instances within a VPC or over an AWS Direct Connect connection. Here, I’ll discuss some performance optimizations impacting cloud storage and the services that use it.
RAID-Optimized EBS Volumes
You can optimize the performance and reliability of your disk-based data using a Redundant Array of Independent Disks (RAID). This is something admins have been doing in the data center for many years, but some RAID configurations can also make a big difference when applied to EBS disks in the AWS cloud.
RAID works by combining the space of multiple drives into a single logical drive and then spreading and/or replicating your data across the entire array. The RAID 0 standard involves data striping, where data is segmented and stored across more than one device, allowing concurrent operations to bypass a single disk’s access limitations. This can greatly speed up IO performance for transaction-heavy operations like busy databases. RAID 0 does not add durability. RAID 1 creates mirrored sets of data on multiple volumes. Traditional RAID 1 arrays don’t use striping or parity, so they won’t provide improved performance, but they do make your data more reliable since the failure of a single volume would not be catastrophic. RAID 1 is common for scenarios where data durability is critical and enhanced performance is not necessary. RAID 5 and RAID 6 configurations can combine both performance and reliability features, but because of IOPS consumption considerations, they’re not recommended by AWS. AWS also does not recommend using RAID-configured volumes as instance boot drives
since the failure of any single drive can leave the instance unbootable. Setting up a RAID array involves creating at least two EBS volumes of the same size and
IOPS setting and attaching them to a running instance. You then use traditional OS tools on the instance—mdadm on Linux and diskpart on Windows—to configure the volumes for RAID. Make sure that the EC2 instance you’re working with has enough available bandwidth to handle the extra load.
Also read this topic: Introduction to Cloud Computing and AWS -1
S3 Cross-Region Replication
Even though S3 is a global service, the data in your buckets has to exist within a physical AWS region. That’s why you need to select a region when you create new buckets. Now, since your data is tied to a single region, there will be times when, for regulatory or performance considerations, you’ll want data “boots” on the ground in more than one place. Replication can be used to minimize latency for geographically dispersed clients or to increase reliability and durability. When configured, S3 Cross-Region Replication (CRR) will automatically sync contents of a bucket in one region with a bucket in a second region. You set up CRR by creating a replication rule for your source bucket (meaning the bucket whose contents will be replicated). You can choose to have all objects in your source replicated or only those whose names match a specified prefix. The replication rule must also define a destination bucket (meaning the bucket to which
your replicated objects will be sent). The destination can be a bucket in a different region in your account, or even one from a different account. Once enabled, copies of objects saved to the source bucket will be created in the destination bucket. When an object is deleted from the source bucket, it will similarly disappear from the destination (unless versioning is enabled on the destination bucket).
Amazon S3 Transfer Acceleration
If your team or customers often find themselves transferring larger files between their local PCs and S3 buckets, then you might benefit from faster transfer rates. S3 Transfer Acceleration adds a per-GB cost to transfers (often in the $0.04 range), but, by routing data through CloudFront edge locations, they can speed things up considerably. To find out whether transfer acceleration would work for your use case, paste the following URL into your browser, specifying an existing bucket name and its AWS region: http://s3-accelerate-speedtest.s3-accelerate.amazonaws.com/en/ accelerate-speed-comparsion.html?region=us-east-1&origBucketName=my-bucket-name You’ll land on a Speed Comparison page that will, over the course of a few minutes, calculate the estimated difference between speeds you’ll get using S3 Direct (the default S3 transfer process) and S3 Accelerated Transfer. If accelerated transfer makes sense for you, you’ll need to enable it for your bucket.
CloudFront and S3 Origins
Besides the static website hosting you explored in Chapter 3, S3 is also an excellent platform for hosting a wide range of files, media objects, resources (like EC2 AMIs), and data. Access to those objects can be optimized using CloudFront. One example might involve creating a CloudFront distribution that uses an S3 bucket containing videos and images as an origin rather than a load balancer sitting in front of EC2 instances. Your EC2-based application could point to the distribution to satisfy client requests for media files, avoiding the bottlenecks and extra costs associated with hosting them locally. Your job as a solutions architect is to assess the kinds of data your deployments will generate and consume and where that data will be most efficiently and affordably kept. More
often than you might at first imagine, the answer to that second question will be S3. The trick is to keep an open mind and be creative.
Database
When designing your data management environment, you’ll have some critical decisions to make. For instance, should you build your own platform on an EC2 instance or leave the heavy infrastructure lifting to AWS by opting for Amazon’s Relational Database Service (RDS)? Doing it yourself can be cheaper and permits more control and customization. But on the other hand, RDS—being a fully managed service—frees you from significant administration worries such as software updates and patches, replication, and network accessibility. You’re responsible only for making basic configuration choices, like these:
■ Choosing the right RDS instance type
■ Optimizing the database through intelligently designing schemas, indexes, and views
■ Optionally configuring option groups to define database functionality that can be applied to RDS instances
■ Optionally configuring parameter groups to define finely tuned database behavior controls that can be applied to RDS instances
Building your own database solutions using EC2 resources gives you control over a much wider range of options, including the following: Consistency, Availability, and Partition Tolerance These are the elements that make up the CAP theorem of distributed data. To prevent data corruption, distributed data store administrators must choose between priorities, because it’s impossible to maintain perfect consistency, availability, and reliability concurrently.
Latency The storage volume type you choose—with its IOPS class and architecture (SSD or magnetic)—will go a long way to determine the read and write performance of your database. Durability How will you protect your data from hardware failure? Will you provision replicated and geographically diverse instances? This was discussed at length in “Chapter 9, The Reliability Pillar.” Scalability Does your design allow for automated resource growth? Nondatabase Hosting Data can sometimes be most effectively hosted on nondatabase platforms such as AWS S3, where tools like the Amazon Redshift Spectrum query engine can effectively connect and consume your data. AWS Redshift (which we discussed in Chapter 5, “Databases”) isn’t the only available data warehouse tool. Various integrations with third-party data management tools are commonly deployed on AWS for highly scalable SQL operations.
Network Optimization and Load Balancing
Cloud computing workloads live and die with network connectivity. So, you’ve got a keen interest in ensuring your resources and customers are able to connect with and access your resources as quickly and reliably as possible. The geolocation and latencybased routing provided by Route 53 and CloudFront are important elements of a strong networking policy, as are VPC endpoints and the high-speed connectivity offered by AWS Direct Connect. High-bandwidth EC2 instance types can also make a significant difference. When manually enabled on a compatible instance type, enhanced networking functionality can give you network speeds of up to 25 Gbps. There are two enhanced networking technologies: Intel 82599 Virtual Function (VF) interface, which can be accessed on instance types including C3, C4, and R3; and Elastic Network Adapter (ENA), which is available on types including G3, H1, and R5. On the following web page, AWS provides clear instructions for enabling enhanced networking from within various flavors of the Linux server OS:
https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/enhanced-networking .html
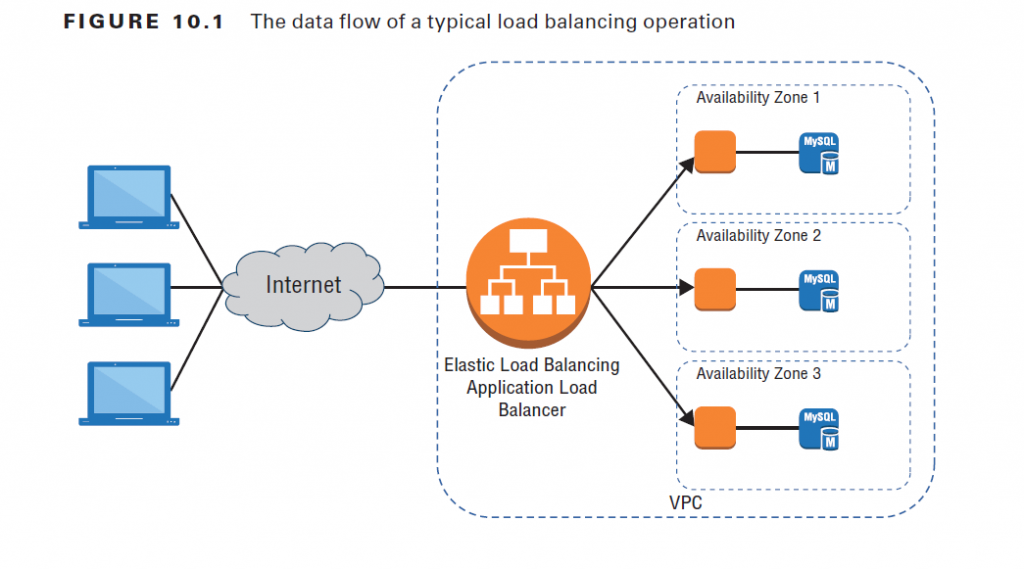
But perhaps the most important network enhancing technology of them all is load balancing. Sooner or later the odds are that you’ll find yourself running multiple instances of your application to keep up with demand. Adding resources to help out a popular app is great, but how are your customers going to find all those new servers? Won’t they all still end up fighting their way into the poor, overworked server they’ve always used? A load balancer is a software service that sits in front of your infrastructure and answers all incoming requests for content. Whether you use a DNS server like Route 53 or CloudFront, the idea is to associate a domain (like example.com) with the address used by your load balancer rather than to any one of your application servers. When the balancer receives a request, it will, as illustrated in Figure 10.1, route it to any one of your backend application servers and then make sure that the response is sent back
to the original client. When you add or remove servers, you only need to update the load balancer software with the addressing and availability status changes, and your customers won’t be any the wiser A load balancer created within EC2 automates much of the process for you. Because the service is scalable, you don’t need to worry about unexpected and violent changes in traffic patterns, and you can design complex relationships that leverage the unique features of
your particular application infrastructure. Originally, a single EC2 load balancer type would handle HTTP, HTTPS, and TCP workloads. That Classic Load Balancer is still available, but it’s been deprecated. Besides the Classic, the Elastic Load Balancing service now offers two separate balancer types: the Application Load Balancer for HTTP and HTTPS and the Network Load Balancer for TCP traffic. The new balancer types come with a number of functions unavailable to the
Classic version, including the ability to register targets outside the VPC and support for containerized applications. The Application Load Balancer operates at the application layer (layer 7 of the Open Systems Interconnection [OSI] model). Layer 7 protocols permit host and path-based routing, which means you can use this load balancer to route traffic among the multiple services of microservice or other tiered architectures. The Network Load Balancer functions at layer four (the transport layer – TCP). Network load balancers are built to manage high volumes and traffic spikes and are tightly integrated with auto scaling, the Elastic Container Service and CloudFormation. TCP balancers should also be used for applications that don’t use HTTP or HTTPS for their internal communications and for AWS managed Virtual Private Network (VPN) connections.
Infrastructure Automation
One of the biggest benefits of virtualization is the ability to describe your resources within a script. Every single service, object, and process within the Amazon cloud can be managed using textual abstractions, allowing for an Infrastructure as Code environment. You’ve already seen this kind of administration through the many AWS CLI examples used in this book. But, building on the CLI and SDK foundations, sophisticated operations can be heavily automated using both native AWS and third-party tools.
CloudFormation
You can represent infrastructure resource stacks using AWS CloudFormation. CloudFormation templates are JSON or YAML-formatted text files that define the complete inventory of AWS resources you would like to run as part of a particular project. CloudFormation templates are easy to copy or export to reliably re-create resource stacks elsewhere. This lets you design an environment to test a beta version of your application and then easily create identical environments for staging and production. Dynamic change can be incorporated into templates by parameterizing key values. This way, you could specify, say, one VPC or instance type for your test environment and a different profile for production. Templates can be created in multiple ways.
■ Using the browser-based drag-and-drop interface
■ Working with prebuilt sample templates defining popular environments such as a LAMP web server or WordPress instance
■ Manually writing and uploading a template document A CloudFormation stack is the group of resources defined by your template. You can launch your stack resources by loading a template and creating the stack. AWS will report when the stack has successfully loaded or, in the event of a failure, will roll back changes. You can update a running stack by submitting a modified version of a template. Deleting a stack will shut down and remove its resources.
People also ask this Questions
- What is a defense in depth security strategy how is it implemented?
- What is AWS Solution Architect?
- What is the role of AWS Solution Architect?
- Is AWS Solution Architect easy?
- What is AWS associate solutions architect?
- Is AWS Solutions Architect Associate exam hard?
Infocerts, 5B 306 Riverside Greens, Panvel, Raigad 410206 Maharashtra, India
Contact us – https://www.infocerts.com
