
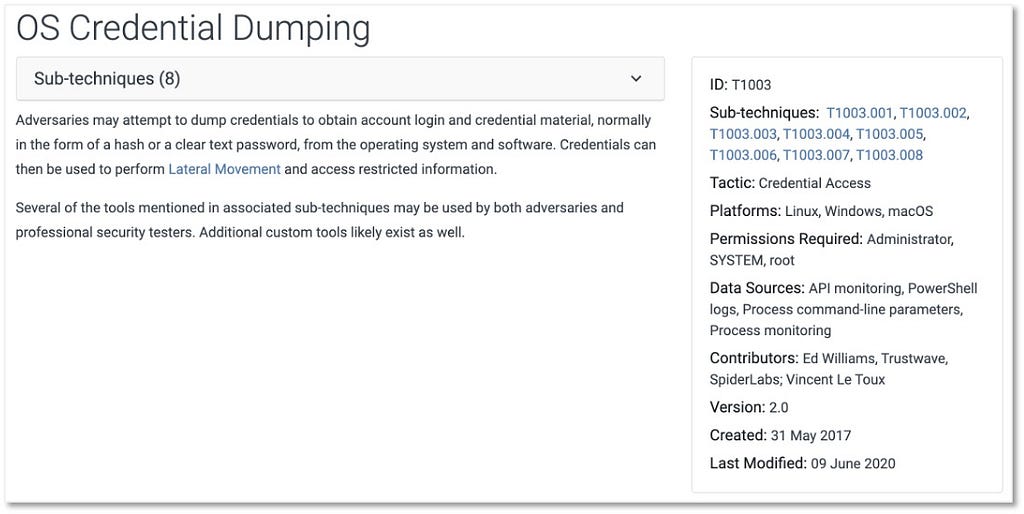
Mitigating Abuse of Android Application Permissions and Special App Accesses
ATT&CK® for Mobile is an ATT&CK matrix of adversary behavior against mobile devices (smartphones and tablets running the Android or iOS/iPadOS operating systems). We started the ATT&CK for Mobile journey with the goal of highlighting the broader mobile threat landscape and adversary behavior exploiting the distinct security architectures in mobile devices. ATT&CK for Mobile was released in 2017 and since then we’ve continued to grow with each new ATT&CK content release, in strong part due to contributions received from many of you in the community.
We’ll be publishing a post formally introducing ATT&CK for Mobile and describing our future plans in the coming weeks and we also plan on posting a series addressing other mobile security technical topics. In this post, we’ll be highlighting how to leverage ATT&CK for Mobile to address abuse of Android application permissions and special app accesses.
Android Permissions and Special App Access in ATT&CK for Mobile
Mobile devices commonly run a variety of applications that have the potential to contain exploitable vulnerabilities or deliberate malicious behaviors. Given these risks, Android (as well as iOS/iPadOS) sandboxes applications, isolating them from one another and from the underlying device. Applications must obtain permission before accessing sensitive resources or performing sensitive operations.
In ATT&CK for Mobile, we describe how Android application permissions are abused by adversaries, and outline methods of defending from abuse. The matrix also details abuse of and defense from what Android calls “special app accesses”, which are requested and managed differently than regular Android permissions. Special app accesses require more complicated defense approaches.
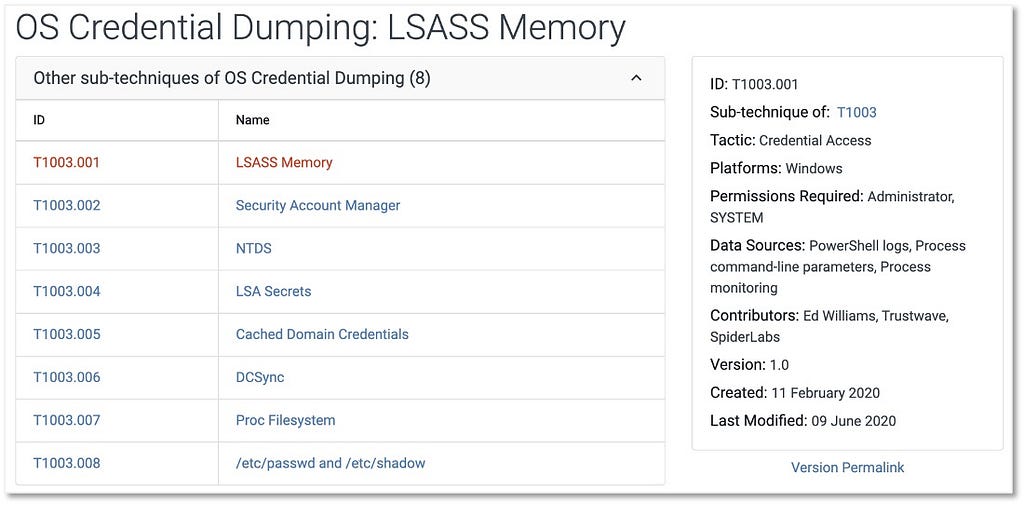
Android Permissions: Abuses and Mitigations
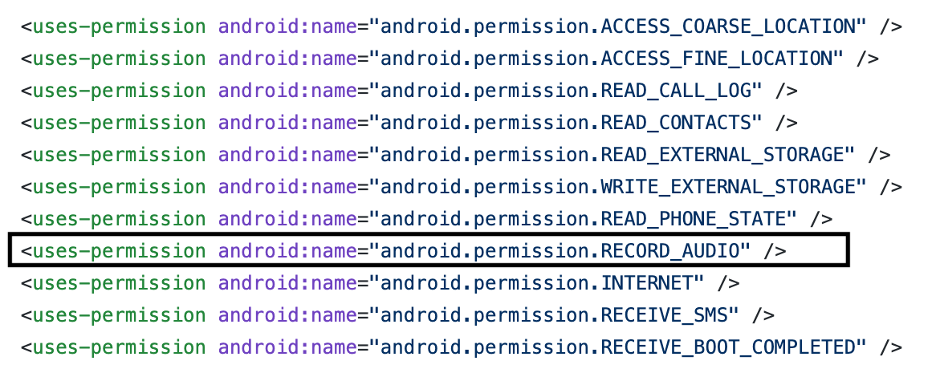
Android requires that applications request permissions before accessing sensitive resources or performing sensitive operations. Applications must declare each permission in their AndroidManifest.xml file using a <uses-permission> entry. Depending on the permission type, they may also need to ask the user to grant the permission at application runtime.
Adversaries may distribute malicious applications that request and make use of permissions, or they may exploit vulnerabilities in legitimate applications that hold permissions.
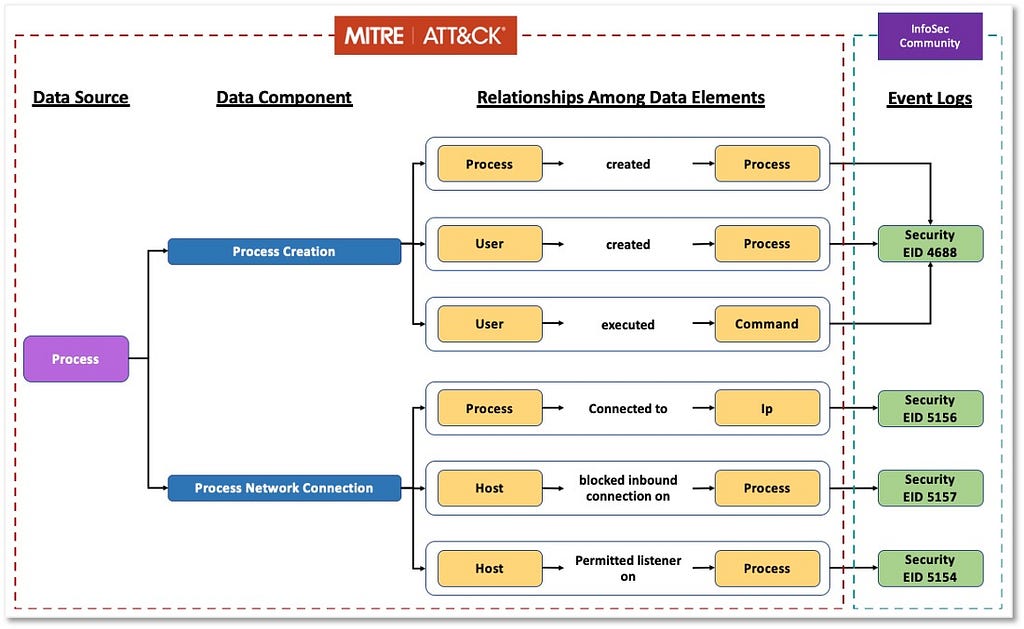
For example, Capture Audio (T1429) describes adversaries calling standard operating system APIs from an application to activate the device microphone and record audio. As the technique description outlines, on Android the application must request and hold the android.permission.RECORD_AUDIO permission. This includes declaring a <uses-permission> entry for the permission in the AndroidManifest.xml file inside the Android application package and asking the user at runtime to grant the permission.[1] Also, Android restricts the ability of applications running in the background to capture audio, although we have encountered applications using the Foreground Persistence (T1541) technique to bypass this restriction.
Enterprises often deploy vetting solutions that automatically assess mobile applications for potentially malicious behaviors, including a scan of the application’s manifest file for declarations of higher risk permissions such as audio recording. Enterprises could then apply additional scrutiny to these applications and, if warranted, could block use of the applications. The applicable ATT&CK for Mobile technique entries feature Application Vetting as a mitigation.
Additionally, using an Enterprise Mobility Management (EMM) system, also commonly known as Mobile Device Management (MDM) or Unified Endpoint Management (UEM), an enterprise can push runtime permission policies to devices to prevent an application from using specific permissions. Runtime permission policies can effectively “neuter” applications, allowing use of the application while blocking potential harmful behaviors, rather than completely blocking use of an application.
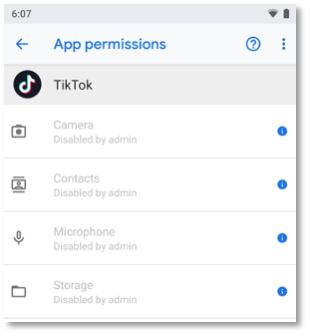
In the example below, enterprise policies are deployed to block TikTok from obtaining sensitive permissions. The policies prevent TikTok from recording videos while still allowing TikTok to view videos. Runtime permission policies are not yet included as a mitigation within ATT&CK for Mobile but will be added in a future release.
Managing Special App Accesses
While adding ATT&CK for Mobile techniques and developing defense descriptions, we encountered what Android refers to as “special app accesses”. According to the Android Platform Security Model paper, these are a “special class of permissions” that “expose more or are higher risk” than other permissions.
Each special app access is managed separately and has a specific way to be requested by applications, adding complexity when vetting applications to detect their use. The standard runtime permission framework cannot be used by enterprises to control use of these accesses by applications. Rather, one-off device management policies exist for some, but not all, of the special app accesses.
ATT&CK for Mobile describes adversary use of special app accesses:
- Accessibility — “used to assist users with disabilities in using Android devices and apps”, but also abused by malicious applications to capture sensitive information from the device screen (T1513) or maliciously inject input to mimic user clicks (T1516)
- Read Notifications — abused by malicious applications to read Android OS notifications containing sensitive data such as one-time authentication codes sent over SMS (T1517)
- Draw over Other Apps (also known as SYSTEM_ALERT_WINDOW) — abused by malicious applications to display prompts on top of other applications to capture sensitive information such as account credentials (T1411)
- Device Administrator — abused by malicious applications to perform administrative operations on the device such as wiping the device contents (T1447)
- Input Method — abused by malicious applications to register as a device keyboard and capture user keystrokes (T1417)
After special app accesses are obtained by applications, they can be managed by the device user through the “Special App Access” menu in the device settings (Settings -> Apps & Notifications -> Advanced -> Special App Access).

Unfortunately, these accesses are handled separately from regular permissions and cannot be managed by enterprises in the same way. There is typically (we identify an exception below) no <uses-permission> entry in the application’s AndroidManifest.xml that can be used to easily identify applications that use each access.
Instead, Android manages each special app access uniquely, making it necessary to perform specific one-off checks to detect each access’s use. For example, applications requesting the ability to read notifications create an Android service with an intent filter for the android.service.notification.NotificationListenerService action. Applications that attempt to read notifications can be detected by searching for a matching service entry in the app’s AndroidManifest.xml file.
The standard runtime permission enterprise management framework cannot be used by enterprises to control use of these accesses by applications. One-off device management policies only exist for a few of the special app accesses. For example, the DevicePolicyManager.setPermittedAccessibilityServices method can be used to impose an “allow list” of applications able to request accessibility access. The setPermittedInputMethods method can be used to impose an allow list of applications permitted to install an input method.
The following table is a non-exhaustive list outlining several special app accesses, the associated ATT&CK for Mobile techniques, how to detect an application’s use of the special app access, and how (as applicable) to use enterprise policies to prevent an application from using them.
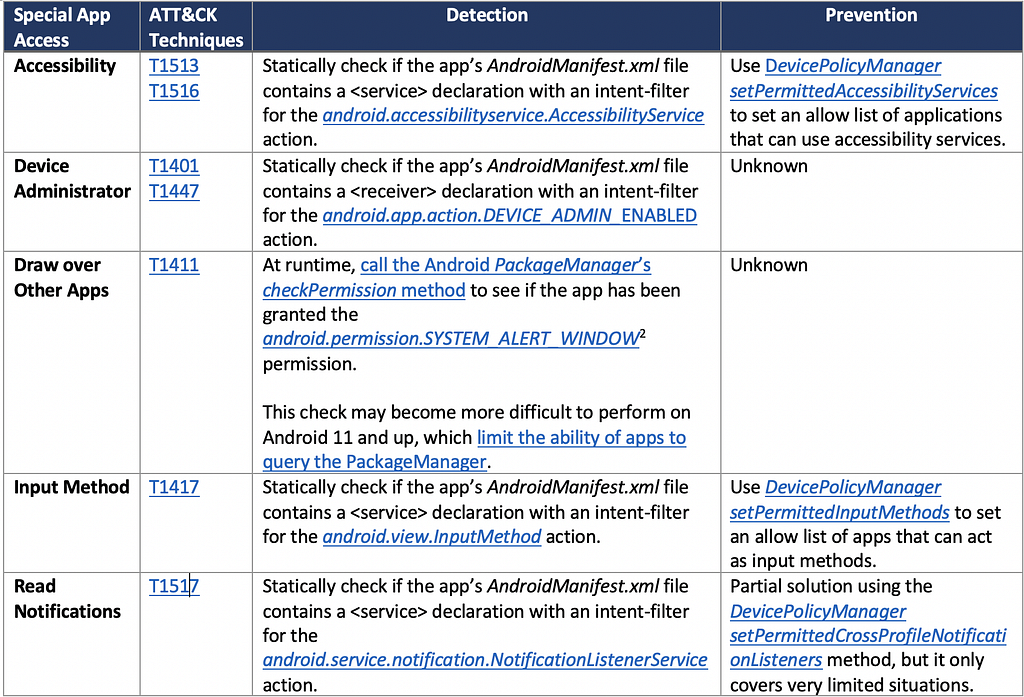
We’re still verifying all of the described detection and prevention methods and are interested in your feedback on the table and if there are any additional elements we should consider. We plan to incorporate into the applicable techniques in a future ATT&CK for Mobile release.
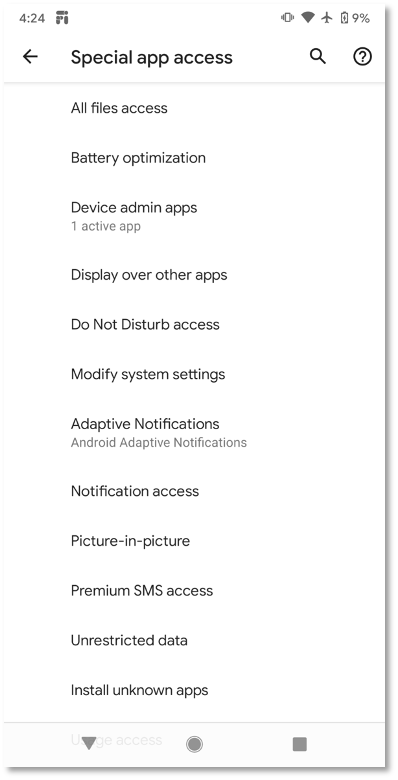
Other special app accesses not yet included in ATT&CK for Mobile include:
- All files access
- Battery optimization
- Do Not Disturb access
- Modify system settings
- Adaptive Notifications
- Picture-in-picture
- Premium SMS access
- Unrestricted data
- Install unknown apps
- Usage access
- VR helper services
- Wi-Fi control
Future Considerations for a Uniform Approach
If Android adjusted to a uniform approach to managing special app accesses, it would simplify the ability to detect or prevent their use. For example, in at least one special app access case, Android requires a <uses-permission> declaration in the AndroidManifest.xml file before an app can obtain the access. Apps must declare the MANAGE_EXTERNAL_STORAGE permission before they can request the “All files access” special app access. The special app access request is still handled outside of the regular means of requesting permissions. If the approach of requiring <uses-permission> declarations were uniformly extended to other special app accesses, it would be easier to detect apps that use them. A uniform approach to push policies to prevent applications from obtaining special app accesses, similar to the existing enterprise management controls on permissions, would also be useful.
Adversary Abuses in the Wild
As we continue to expand the Mobile knowledge base and update and develop new techniques, we welcome any input on adversary abuse of special app accesses in the wild! We’re also interested in your feedback on how to detect apps that use each special app access and how to prevent apps from using each special app access.
You can connect with us at [email protected].
© 2021 The MITRE Corporation. All Rights Reserved. Approved for Public Release; Distribution Unlimited. Public Release Case Number 21–0835.
[1] Similarly, on iOS/iPadOS, each application must include the NSMicrophoneUsageDescription key in its Info.plist file (part of the application package) and must ask the user for permission to use the microphone.
[2] The Android OS grants the SYSTEM_ALERT_WINDOW permission to keep track of apps that hold the Draw over Other Apps special app access, but apps themselves cannot directly request SYSTEM_ALERT_WINDOW through the regular means of requesting permissions.
Mitigating Abuse of Android Application Permissions and Special App Accesses was originally published in MITRE ATT&CK® on Medium, where people are continuing the conversation by highlighting and responding to this story.



































{kind=link}