
Third-Party Automation Solutions
Of course, you can also create your own infrastructure automation scripts using Bash or Windows PowerShell. Such scripts can connect directly to your AWS account and launch, manipulate, and delete resource stacks. Besides Bash and PowerShell scripts, third-party configuration management tools such as Puppet, Chef, and Ansible can be used to closely manage AWS infrastructure. Beyond simply defining and launching resource stacks, these managers can also actively engage with your deployments through operations such as configuration enforcement (to continuously ensure your resources aren’t drifting away from their configuration goals), version control (to ensure your code and software packages are kept up-to-date), and change management. The potential value of configuration management tools for cloud deployments is so obvious that AWS has a managed service dedicated entirely to integrating Chef and Puppet
tools: AWS OpsWorks.
AWS OpsWorks: Chef
Using OpsWorks, you can build an infrastructure controlled by Chef by adding a stack (a container for EC2 instances and related resources) and one or more layers. Layers are the definitions that add functionality to your stack. A stack might include a Node.js app server layer along with a load balancer, an Amazon EC2 Container Service (ECS) cluster, or an RDS database instance. Chef recipes for managing your infrastructure can also be added as layers. OpsWorks Chef deployments also include one or more apps. An app points to the application code you want to install on the instances running in your stack along with some
metadata providing accessibility to a remote code repository.
AWS OpsWorks: Puppet
Firing up OpsWorks for Puppet Enterprise will allow you to launch an EC2 instance as a Puppet Master server, configure the R10k environment and module toolset, and give it access to your remote code repo. Once a server is running and you’ve logged in using the provided credentials, you’ll be ready to begin deploying your application to Puppet nodes. Your OpsWorks experience will probably be more successful if you’re already familiar with administrating either Chef or Puppet locally.
Continuous Integration and Continuous Deployment
If your organization’s application is built from the code written by multiple developers and if you regularly update your application, then you’re probably already using some kind of continuous integration and continuous deployment (CI/CD) process. CI/CD seeks to automate the workflow that moves a project from source code, through compiling (the build), and on to deployment. The goal is to provide a reliable, fast, and bug-free way to stay on top of application change. The four AWS services that make up their Developer Tools (described together at https://aws.amazon.com/tools/) can facilitate CI/CD through an integrated environment for source code version control, application builds and testing, and then the final push to production—either within AWS or wherever else it needs to go.
AWS CodeCommit
CodeCommit is a Git-compatible code repository where you can safely store and access your code. Why CodeCommit and not GitHub or GitLab? It’s for several reasons: because CodeCommit is deeply integrated into the AWS environment, because you can apply granular access control through AWS IAM, and because, as an AWS service, CodeCommit is highly scalable.
AWS CodeBuild
When team members are ready to commit new code versions, you’d ideally want their updates to be compiled and run within your test environment immediately. But maintaining a build server 24/7 and configuring it with access permissions appropriate for each member of your team can be an expensive and complicated process. CodeBuild is a fully managed, virtualized build server that’s scalable. That means it can handle as many resource-hungry commits and builds as you can throw at it, but it will cost you money only for the time you’re actually using it. CodeBuild will respond to a commit by compiling, testing, and packaging your code CodeBuild can handle code from S3, CodeCommit, Bitbucket, GitHub, and GitHub Enterprise, and it’s comfortable with Java, Python, Node.js, Ruby, Go, Android, .NET Core for Linux, and Docker.
AWS CodeDeploy
You use CodeDeploy to pull code from either CodeBuild or your own build server and push it to applications running on either Amazon EC2 or AWS Lambda. EC2 instances—organized into deployment groups—are controlled by an installed agent that regularly polls the CodeDeploy service for pending application revisions. Revisions are executed based on the instructions in an application specification (AppSpec) file, which maps the code, source files, and scripts that make up your application with the deployment targets.
AWS CodePipeline
CodePipeline is a kind of orchestration tool that can automatically manage all the parts of your CI/CD process. As an example, the service can be set to monitor CodeCommit (or a third-party service like GitHub) for updates; push the new code through the build process using tools like CodeBuild, Jenkins, and TeamCity; and then deploy the revision using AWS services like CodeDeloy, Elastic Beanstalk, and CloudFormation. Figure 10.2 illustrates the role played by each of the AWS Developer Tools in a typical CI/CD deployment system.
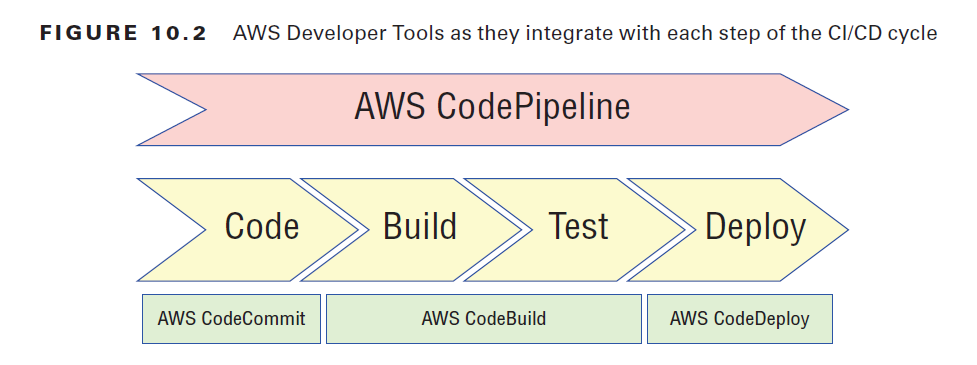
Reviewing and Optimizing Infrastructure Configurations
If you want to achieve and maintain high-performance standards for your applications, you’ll need solid insights into how they’re doing. To get those insights, you’ll need to establish a protocol for monitoring change. Your monitoring should have these four goals:
■ Watch for changes to your resource configurations. Whether a change occurred through the intervention of a member of your admin team or through an unauthorized hacker, it’s important to find out fast and assess the implications. The AWS Config service—discussed in Chapter 7, “CloudTrail, CloudWatch, and AWS Config”—should give you all the information you need to get started.
■ Watch AWS for announcements of changes to its services. Amazon is a busy company, and it regularly releases updates to existing services and entirely new services. To be sure your current configuration is the best one for your needs, keep up with the latest available features and functionality. One way to do that is by watching the AWS Release Notes page (https://aws.amazon.com/releasenotes/). You can subscribe to update alerts through the AWS Email Preference Center (https://pages.awscloud .com/communication-preferences.html).
■ Passively monitor the performance and availability of your application. Passive monitoring is primarily concerned with analyzing historical events to understand what—if anything—went wrong and how such failures can be avoided in future. The most important tool for this kind of monitoring is system logs. On AWS, the richest source of log data is CloudWatch, as you learned in Chapter 7.
■ Actively test the performance and availability of your application to proactively identify—and fix—potential problems before they can cause any damage. This will usually involve load testing.
Load Testing
One particularly useful form of active infrastructure monitoring is load—or stress—testing. The idea is to subject your infrastructure to simulated workloads and carefully observe how it handles the stress. You can try to devise some method of your own that will generate enough traffic of the right kind to create a useful simulation, but there are plenty of third-party tools available to do it for you. Search the AWS Marketplace site (https://aws .amazon.com/marketplace) for load testing. In most cases—so you don’t prevent your actual users from accessing your application as normal—you should run your stress tests against some kind of test environment that’s configured to run at production scale. Orchestration tools like CloudFront or, for containers, Amazon Elastic Container Service (ECS), can be useful for quickly building such an environment. Your application might not respond quite the same way to requests from different parts of the world. So, you should try to simulate traffic from multiple geographical origins into your testing. Make sure that your testing doesn’t break any AWS usage rules. Before launching some kinds of vulnerability or penetration tests against your infrastructure, for instance, you need to request explicit permission from AWS. You can find out more on Amazon’s Vulnerability and Penetration Testing page: https://aws.amazon.com/security/penetration-testing. Of course, don’t forget to set CloudWatch up in advance so you can capture the realtime results of your tests. To get the most out of your testing, it’s important to establish performance baselines and consistent key performance indicators (KPIs) so you’ll have an objective set of standards against which to compare your results. Knowing your normal aggregate cumulative cost per request or time to first byte, for instance, will give important context to what your testing returns.
Also read this topic: Introduction to Cloud Computing and AWS -1
Visualization
All the active and passive testing in the world won’t do you any good if you don’t have a user-friendly way to consume the data it produces. As you saw in Chapter 7, you can trigger notifications when preset performance thresholds are exceeded. Having key team members receive Simple Notification Service (SNS) messages or email alerts warning them about abnormal events can be an effective way to make your monitoring data count. In many cases, however, there’s no replacement for good, old-fashioned charts and graphs. Some AWS services have their own built-in visualizations. With an instance selected in the EC2 Instances Dashboard, as an example, you can click the Monitoring tab in the lower half of the screen and view a dozen or so metrics rendered as data charts.
But the place where you’ll get the greatest visualization bang for your buck is in CloudWatch Dashboards. CloudWatch lets you create multiple Dashboards.
Optimizing Data Operations
Moving data efficiently is pretty much the whole story when it comes to successful applications. Your code may be a thing of great beauty, but if everything slows down while you’re waiting for a large data transfer over a weak connection, then it’s mostly wasted effort. Sometimes you can’t control the network connection you’re working with, and sometimes you can’t reduce the volume of data in play. But it’s usually possible to apply some clever data management tricks to speed things up noticeably. Data caching, sharding, compression, and decoupling are good examples of the kinds of tricks you can use, so let’s talk
about how they work on AWS.
Caching
Does your application provide lots of frequently accessed data like a product catalog or other media that’s kept in your S3 buckets or a relational database? So, why not move copies of the data closer to your clients? A caching solution does just that. If an object is likely to be requested repeatedly, a copy can be written to system memory on a server—or a purpose-built cache database—from which it can be retrieved much more quickly. Subsequent requests for that data will see the cached copy rather than having to wait for the time it would take to read from the source. The cached copy will remain the authoritative version until its maximum time to live (TTL) is reached, at which point it will be flushed and replaced by an updated version that’s read from the data source.
Amazon ElastiCache
An ElastiCache cluster consists of one or more nodes. As Figure 10.3 illustrates, a node is a compute instance—built from an EC2 instance type you select—that does the actual work of processing and serving data to your clients. The number of nodes and the particular instance type you choose will depend on the demands your clients are likely to place on the application. Finding the ideal configuration combination that’s best for your needs will require some of the same considerations you’d use to provision for any EC2 workload.
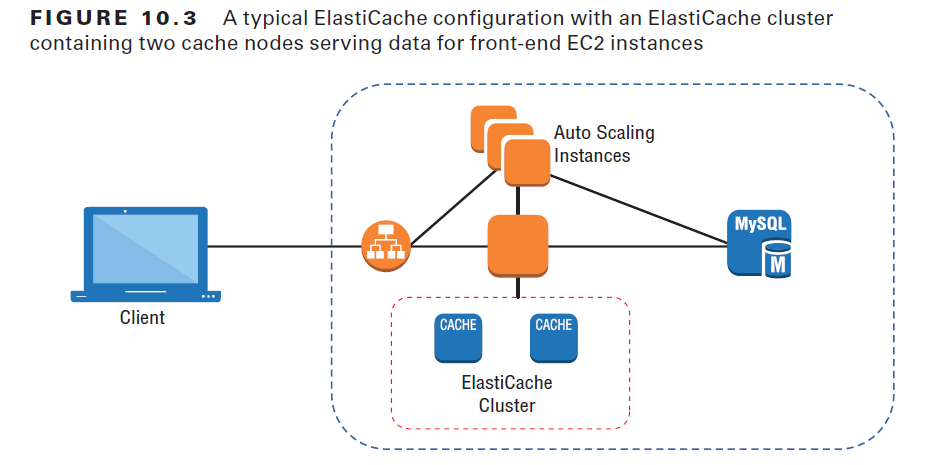
ElastiCache clusters can be created using either one of two engines: Memcached or Redis. Memcached can be simpler to configure and deploy, is easily scalable, and, because it works with multiple threads, can run faster. However, because it reads and writes only objects (blobs) as in-memory key-value data stores, Memcached isn’t always flexible enough to meet the needs of all projects. Redis, on the other hand, supports more complex data types such as strings, lists, and sets. Data can also be persisted to a disk, making it possible to snapshot data for later recovery. Redis lets you sort and rank data, allowing you to support, say, an online gaming application that maintains a leaderboard ranking the top users. The fact that Redis can persist data makes it possible to use Redis to maintain session caching, potentially improving performance. Typically, ElastiCache will make the current version of both Redis and Memcached available, along with a few previous versions. This makes it possible to support as wide a range of application needs as possible. Once your ElastiCache cluster is running, you can retrieve its endpoint from the ElastiCache Dashboard and connect to the cluster from your application. For a WordPress instance, for example, this can be as simple as adding a single line to the wp-config.php file containing something like the following syntax:
define(‘WP_REDIS_HOST’, ‘your_cluster_name.amazonaws.com’);
You can enjoy the benefits of caching without using ElastiCache. For some use cases, you might want to save some money and simply run a reverse proxy like Varnish on your actual EC2 instance.
Other Caching Solutions
Besides caching at the application level, you can also achieve performance gains using broadly similar techniques on the data in your database. As you saw in Chapter 5, you can add as many as five read replicas to a running database instance in RDS (RDS Aurora instances can have as many as 15). Read replicas are
available for RDS MySQL, MariaDB, PostgreSQL, and Aurora. The replica will be an exact copy of the original but will be read-only. By routing some of your traffic to the replica, you lighten the load on the source database, improving response times for both copies. In addition to performance benefits, you can also, if necessary, promote a read replica to your primary database should the original fail. Effectively, a read replica is a kind of cache that leverages relatively cheap storage overheads to provide quick and highly available copies of your data. Another type of caching—which you saw in Chapter 8—is CloudFront. As you’ll
remember, a CloudFront distribution can cache copies of S3-based media on edge locations spread around the world and serve requests from the copy located closest to the client.
Partitioning/Sharding
Traffic volume on your RDS database can increase to the point that a single instance simply can’t handle it. While vertical scaling may not be an option, horizontal scaling through partitioning (or sharding) can make a big difference. While not as simple a solution as the read-only read replicas just discussed, partitioning can be configured by adding appropriate logic to the application layer so client requests are directed to the right endpoints. Sending data in real time through Amazon Kinesis Streams—using the Amazon DynamoDB Streams Kinesis Adapter—lets you process streams of data records in DynamoDB databases. Kinesis organizes records into shards that contain data along with critical meta information. If one shard hits a limit, the workload can be further distributed by subdividing it into multiple shards. As it’s highly scalable and fully managed, Kinesis streams maintain near-real-time performance and, by extension, can have a significant impact on overall data processing performance.
Compression
If bandwidth is a finite resource and it’s not practical to reduce the volume of data you’re regularly transferring, there’s still hope. You can either reduce the size of your data or bypass the network with its built-in limits altogether. How do you reduce data size? By borrowing a solution that, once upon a time, was a
necessary part of working with expensive and limited storage space. Are you old enough to remember how we used to fit a full operating system along with our program and work files onto a 10 MB drive? Disk compression. Storage is no longer a serious problem, but network transfers are. You can, therefore,
stretch the value you get from your network connections by compressing your data before sending it. This is something that can be incorporated into your application code. But it’s also used directly within some AWS services. CloudFront, for instance, can be configured to automatically compress the files sent in response to client requests, greatly reducing download times. And bypassing the network? You can ask Amazon to send you a physical petabyte-sized storage device called a Snowball. You copy your archives onto the encrypted device and then ship it back to Amazon. Within a short time, your data will be uploaded to buckets in S3.
People also ask this Questions
- What is a defense in depth security strategy how is it implemented?
- What is AWS Solution Architect?
- What is the role of AWS Solution Architect?
- Is AWS Solution Architect easy?
- What is AWS associate solutions architect?
- Is AWS Solutions Architect Associate exam hard?
Infocerts, 5B 306 Riverside Greens, Panvel, Raigad 410206 Maharashtra, India
Contact us – https://www.infocerts.com
